文字コード 追加で教えて欲しいです への返答

投稿で使用できる特殊コードの説明。(別タブで開きます。)
以下の返答は逆順(新しい順)に並んでいます。
投稿者 snowmansnow (社会人)
投稿日時
2021/11/21 18:08:52
こんばんは、
変な質問をしてしまいました、
魔界の仮面弁士様の2021/10/6 10:46:33の投稿で、
基底文字の話を理解していませんでした。
>この基底文字は基本多言語面(BMP)にあります。
>2の異体字セレクタは IVS の [VS1]、3の異体字セレクタは IVS の [VS17] です。
変な質問でしたので、今回は解決とさせて頂きます。
VS1の調べ方は、またの機会にお願いいたします。
皆さんごめんなさい。
投稿者 snowmansnow (社会人)
投稿日時
2021/11/18 20:59:29
こんばんは、
IVSの異体字セレクタはGekka様のプログラムでFont毎に含まれているか、
皆さんのお陰でわかるようになりましたが、
SVSの異体字セレクタはどのように調べたら良いのでしょうか?
https://github.com/adobe-type-tools/pancjkv-ivd-collectionの
①IVD_Sequences.txtや
http://www.unicode.org/Public/UNIDATA/StandardizedVariants.txtの
②StandardizedVariants.txtに
コードポイントと異体字セレクタの一覧表があると思ったのですが、
①と②に、重複して同じコードポイントが、あるようでした・・・
20122とか34BBとか533Fとか、771個も同じでした。
全く違う体系だと思ったのですが、何故なのでしょうか?
質問がおかしいのかもしれませんが、宜しくお願いします。
IVSの異体字セレクタはGekka様のプログラムでFont毎に含まれているか、
皆さんのお陰でわかるようになりましたが、
SVSの異体字セレクタはどのように調べたら良いのでしょうか?
https://github.com/adobe-type-tools/pancjkv-ivd-collectionの
①IVD_Sequences.txtや
http://www.unicode.org/Public/UNIDATA/StandardizedVariants.txtの
②StandardizedVariants.txtに
コードポイントと異体字セレクタの一覧表があると思ったのですが、
①と②に、重複して同じコードポイントが、あるようでした・・・
20122とか34BBとか533Fとか、771個も同じでした。
全く違う体系だと思ったのですが、何故なのでしょうか?
質問がおかしいのかもしれませんが、宜しくお願いします。
投稿者 snowmansnow (社会人)
投稿日時
2021/11/13 18:41:33
こんばんは、魔界の仮面弁士様、るきお様
エラーの理由だけでなく、沢山沢山ありがとうございます。
エラーは御教授いただいたコードで修正確認できました。
バイナリエディタも最初Fontsフォルダに触れなくて、困りましたが、
コピーして開くことができました。
御教授頂いたバイナリは、見ることができましたが、消化不良で、
見て確認できた所までです。
少しずつ勉強していきたいと思います。
Gekka様のVBも、IVSが見当たらなかったらエラーになっていましたので、
少し改造して、見当たらなかったら999999を返すようにして、
Public Shared Function FindISVS(ByVal targetFontName As String, ByVal targetChar As UInteger) As List(Of UInteger)
On Error GoTo ErrLabel
Dim fontFile As System.IO.FileInfo = FindFont(targetFontName)
If (fontFile IsNot Nothing) Then
For Each ttf As TTF In TTC.Read(fontFile.FullName, TTFDataReadTypes.Names Or TTFDataReadTypes.IVS)
Return ttf.IVSMap.Item(targetChar)
Next
End If
Return Nothing
'Return New System.IO.FileInfo("C:\Users\Y2\AppData\Local\Microsoft\Windows\Fonts\ipamjm.ttf")
ErrLabel:
'https://www.sejuku.net/blog/35484
Dim er As UInteger
Dim list1a = New List(Of UInteger)
'https://atmarkit.itmedia.co.jp/ait/articles/1703/01/news042.html
er = 999999
list1a.Add(er)
Return list1a
End Function
Public Shared Function FindISV(ByVal targetFontName As String, ByVal targetChar As Char) As List(Of UInteger)
Dim fontFile As System.IO.FileInfo = FindFont(targetFontName)
If (fontFile IsNot Nothing) Then
For Each ttf As TTF In TTC.Read(fontFile.FullName, TTFDataReadTypes.Names Or TTFDataReadTypes.IVS)
Return ttf.IVSMap.Item(AscW(targetChar))
Next
End If
Return Nothing
End Function
IVD_Sequences.txtの全部(丸めて)のコードの有無をテキストファイルに出力して確認したりしています。
文字は、とても面白く難しいので、今後もがんばって行きたいと思います。
WIN11も出て、とても忙しいと思いますが、とても沢山時間を割いて頂き、
大変ありがく恐縮です。
皆さん、また御指導宜しくお願いします。
投稿者 魔界の仮面弁士 (社会人)
投稿日時
2021/11/13 17:07:01
> 各レコードとその開始位置を、以下のように読み取れます。
この中の "cmap", "hhea", "head", "hmtx", "maxp", "name", "OS/2", "post" は
どのフォントファイルにも含まれる必須レコードです。
で…今回欲しいのは、Naming table ということでしたよね。お待たせしました。
ようやく本命の TableDirectory[0].TableRecord["name"].nameRecord[*] な領域です。
ここに、フォントファミリ名や著作権表示が記録されています。
今回用いた mingliub.ttc には 3 つのフォントが含まれており、
それぞれが 35 個の Naming table レコードを含んでいましたが
Gekka さんのコードではすべてを読み取ることができません。
platformID が 3 (Windows) のもの以外は無視する設計になっているためです。
すべてのデータを読み取りたい場合には、NameRecord.ReadData メソッドや
TTF.GetNames メソッド内の platformID 判定部を修正する必要があります。
platformID, encodingID, languageID の意味についてはこのあたり。
https://docs.microsoft.com/en-us/typography/opentype/spec/name#platform-encoding-and-language-ids
一つの nameID に対して、platformID, encodingID, languageID の異なる
複数の組み合わせが同時に収録されています。
今回のケースだと、nameID が 13, 14, 19 の物は、Windows / 米語 だけの収録でしたが、
nameID が 0~7 のレコードに関しては、Mac を含む下記 4 言語で収録されていました。
nameID = 19 "SampleText" の内容は "𠀀𠀁𠀂𠀃𠀄\r𦬣𦬤𦬥𦬦𦬧\r𦩒𦩓𦩔𦩕𦩖\r𨣫𨣬𨣭𨣮𨣯" なのに
収録されている languageID が 英語(米語) だけだったのが、ちょっと違和感。
この中の "cmap", "hhea", "head", "hmtx", "maxp", "name", "OS/2", "post" は
どのフォントファイルにも含まれる必須レコードです。
で…今回欲しいのは、Naming table ということでしたよね。お待たせしました。
ようやく本命の TableDirectory[0].TableRecord["name"].nameRecord[*] な領域です。
ここに、フォントファミリ名や著作権表示が記録されています。
位置 : バイナリ : 説明
----------------- : ----------- : --------------------------------------
022F3B6A-022F3B6B : 00,23 : nameRecord.count = 0x23
022F3B6C-022F3B6D : 01,AA : storageOffset。文字列が 0x22F3D12 にあることを示す。
022F3B6E-022F3B6F : 00,01 : nameRecord[0].platformID = 1
022F3B70-022F3B71 : 00,00 : nameRecord[0].encodingID = 0
022F3B72-022F3B73 : 00,00 : nameRecord[0].languageID = 0
022F3B74-022F3B75 : 00,00 : nameRecord[0].nameID = 0
022F3B76-022F3B77 : 00,18 : nameRecord[0].length = 0x18
022F3B78-022F3B79 : 00,00 : nameRecord[0].stringOffset = 0
022F3B7A-022F3B7B : 00,01 : nameRecord[1].platformID = 1
022F3B7C-022F3B7D : 00,00 : nameRecord[1].encodingID = 0
022F3B7E-022F3B7F : 00,00 : nameRecord[1].languageID = 0
022F3B80-022F3B81 : 00,01 : nameRecord[1].nameID = 1
022F3B82-022F3B83 : 00,0C : nameRecord[1].length = 0x0C
022F3B84-022F3B85 : 00,18 : nameRecord[1].stringOffset = 0x18
022F3B86-022F3B87 : 00,01 : nameRecord[2].platformID = 1
022F3B88-022F3B89 : 00,00 : nameRecord[2].encodingID = 0
022F3B8A-022F3B8B : 00,00 : nameRecord[2].languageID = 0
022F3B8C-022F3B8D : 00,02 : nameRecord[2].nameID = 2
022F3B8E-022F3B8F : 00,07 : nameRecord[2].length = 0x07
022F3B90-022F3B91 : 00,24 : nameRecord[2].stringOffset = 0x24
以下略
----------------- : ----------- : --------------------------------------
022F3B6A-022F3B6B : 00,23 : nameRecord.count = 0x23
022F3B6C-022F3B6D : 01,AA : storageOffset。文字列が 0x22F3D12 にあることを示す。
022F3B6E-022F3B6F : 00,01 : nameRecord[0].platformID = 1
022F3B70-022F3B71 : 00,00 : nameRecord[0].encodingID = 0
022F3B72-022F3B73 : 00,00 : nameRecord[0].languageID = 0
022F3B74-022F3B75 : 00,00 : nameRecord[0].nameID = 0
022F3B76-022F3B77 : 00,18 : nameRecord[0].length = 0x18
022F3B78-022F3B79 : 00,00 : nameRecord[0].stringOffset = 0
022F3B7A-022F3B7B : 00,01 : nameRecord[1].platformID = 1
022F3B7C-022F3B7D : 00,00 : nameRecord[1].encodingID = 0
022F3B7E-022F3B7F : 00,00 : nameRecord[1].languageID = 0
022F3B80-022F3B81 : 00,01 : nameRecord[1].nameID = 1
022F3B82-022F3B83 : 00,0C : nameRecord[1].length = 0x0C
022F3B84-022F3B85 : 00,18 : nameRecord[1].stringOffset = 0x18
022F3B86-022F3B87 : 00,01 : nameRecord[2].platformID = 1
022F3B88-022F3B89 : 00,00 : nameRecord[2].encodingID = 0
022F3B8A-022F3B8B : 00,00 : nameRecord[2].languageID = 0
022F3B8C-022F3B8D : 00,02 : nameRecord[2].nameID = 2
022F3B8E-022F3B8F : 00,07 : nameRecord[2].length = 0x07
022F3B90-022F3B91 : 00,24 : nameRecord[2].stringOffset = 0x24
以下略
今回用いた mingliub.ttc には 3 つのフォントが含まれており、
それぞれが 35 個の Naming table レコードを含んでいましたが
Gekka さんのコードではすべてを読み取ることができません。
platformID が 3 (Windows) のもの以外は無視する設計になっているためです。
すべてのデータを読み取りたい場合には、NameRecord.ReadData メソッドや
TTF.GetNames メソッド内の platformID 判定部を修正する必要があります。
platformID, encodingID, languageID の意味についてはこのあたり。
https://docs.microsoft.com/en-us/typography/opentype/spec/name#platform-encoding-and-language-ids
一つの nameID に対して、platformID, encodingID, languageID の異なる
複数の組み合わせが同時に収録されています。
今回のケースだと、nameID が 13, 14, 19 の物は、Windows / 米語 だけの収録でしたが、
nameID が 0~7 のレコードに関しては、Mac を含む下記 4 言語で収録されていました。
platformID : encodingID : languageID
------------- : --------------- : --------------------------------
1 (Macintosh) : 0 (Roman) : 0x0000 (English)
3 (Windows) : 1 (Unicode BMP) : 0x0404 (Chinese/Taiwan)
3 (Windows) : 1 (Unicode BMP) : 0x0409 (English/United States)
3 (Windows) : 1 (Unicode BMP) : 0x0409 (Chinese/Hong Kong S.A.R.)
------------- : --------------- : --------------------------------
1 (Macintosh) : 0 (Roman) : 0x0000 (English)
3 (Windows) : 1 (Unicode BMP) : 0x0404 (Chinese/Taiwan)
3 (Windows) : 1 (Unicode BMP) : 0x0409 (English/United States)
3 (Windows) : 1 (Unicode BMP) : 0x0409 (Chinese/Hong Kong S.A.R.)
nameID = 19 "SampleText" の内容は "𠀀𠀁𠀂𠀃𠀄\r𦬣𦬤𦬥𦬦𦬧\r𦩒𦩓𦩔𦩕𦩖\r𨣫𨣬𨣭𨣮𨣯" なのに
収録されている languageID が 英語(米語) だけだったのが、ちょっと違和感。
投稿者 (削除されました) ()
投稿日時
2021/11/13 15:31:45
(削除されました)
投稿者 魔界の仮面弁士 (社会人)
投稿日時
2021/11/13 14:15:11
このまま TableDirectory[0].TableRecord[*] の解析も続けます。
データ位置を示すオフセットは、ファイル先頭 を 0 とした値で記録されています。
こんな感じで解析していくと、最初のフォントに記録されている
各レコードとその開始位置を、以下のように読み取れます。
Gekka さんのコードでいうと、
TTF.GetNames メソッドで "name" タグのレコード、
TTF.GetIVSMap メソッドで "cmap" タグのレコードを読む実装です。
ということで、今度は "name" タグの解析。
Gekka さんのコードで実行した場合、NamingTable のインスタンスはこうなります。
.format = 0
.nameRecords.Count = 35
.langTagRecords.Count = 0
データ位置を示すオフセットは、ファイル先頭 を 0 とした値で記録されています。
位置 : バイナリ : 説明
--------- : ------------ : --------------------------------------
0024-0027 : 00,01,00,00 : version = 0x00010000
0028-0029 : 00,12 : numTables = 0x12
0030-0033 : 47,53,55,42 : TableRecord[0] は "GSUB" レコード(Glyph Substitution Table)
0034-0037 : 2F,55,3F,5D : チェックサム
0038-003B : 00,00,03,A8 : GSUB レコードの位置 (ファイルの先頭からの位置)
003C-003F : 00,00,00,4C : GSUB レコードの長さ (0x4C すなわち 76 バイト)
0040-0043 : 47,53,55,42 : TableRecord[1] は "OS/2" レコード(OS/2 and Windows Metrics Table)
0044-0047 : 60,AA,D7,06 : チェックサム
0048-004B : 00,00,03,F4 : OS/2 レコードの位置 (ファイルの先頭からの位置)
004C-004F : 00,00,00,60 : OS/2 レコードの長さ (0x60 すなわち 96 バイト)
--------- : ------------ : --------------------------------------
0024-0027 : 00,01,00,00 : version = 0x00010000
0028-0029 : 00,12 : numTables = 0x12
0030-0033 : 47,53,55,42 : TableRecord[0] は "GSUB" レコード(Glyph Substitution Table)
0034-0037 : 2F,55,3F,5D : チェックサム
0038-003B : 00,00,03,A8 : GSUB レコードの位置 (ファイルの先頭からの位置)
003C-003F : 00,00,00,4C : GSUB レコードの長さ (0x4C すなわち 76 バイト)
0040-0043 : 47,53,55,42 : TableRecord[1] は "OS/2" レコード(OS/2 and Windows Metrics Table)
0044-0047 : 60,AA,D7,06 : チェックサム
0048-004B : 00,00,03,F4 : OS/2 レコードの位置 (ファイルの先頭からの位置)
004C-004F : 00,00,00,60 : OS/2 レコードの長さ (0x60 すなわち 96 バイト)
こんな感じで解析していくと、最初のフォントに記録されている
各レコードとその開始位置を、以下のように読み取れます。
[ 0] = "GSUB" (000003A8)
[ 1] = "OS/2" (000003F4)
[ 2] = "cmap" (00000454)
[ 3] = "cvt " (000006D0)
[ 4] = "fpgm" (000006D8)
[ 5] = "gasp" (000006EC)
[ 6] = "glyf" (000006FC)
[ 7] = "head" (022AB4E8)
[ 8] = "hhea" (022AB520)
[ 9] = "hmtx" (022AB544)
[10] = "loca" (022C388C)
[11] = "maxp" (022F3B08)
[12] = "meta" (022F3B28)
[13] = "name" (022F3B68)
[14] = "post" (022F4248)
[15] = "prep" (022F4268)
[16] = "vhea" (022F427C)
[17] = "vmtx" (022F42A0)
[ 1] = "OS/2" (000003F4)
[ 2] = "cmap" (00000454)
[ 3] = "cvt " (000006D0)
[ 4] = "fpgm" (000006D8)
[ 5] = "gasp" (000006EC)
[ 6] = "glyf" (000006FC)
[ 7] = "head" (022AB4E8)
[ 8] = "hhea" (022AB520)
[ 9] = "hmtx" (022AB544)
[10] = "loca" (022C388C)
[11] = "maxp" (022F3B08)
[12] = "meta" (022F3B28)
[13] = "name" (022F3B68)
[14] = "post" (022F4248)
[15] = "prep" (022F4268)
[16] = "vhea" (022F427C)
[17] = "vmtx" (022F42A0)
Gekka さんのコードでいうと、
TTF.GetNames メソッドで "name" タグのレコード、
TTF.GetIVSMap メソッドで "cmap" タグのレコードを読む実装です。
ということで、今度は "name" タグの解析。
位置 : バイナリ : 説明
----------------- : ----------- : --------------------------------------
022F3B68-022F3B69 : 00,00 : version = 0。Naming table version 0 を意味します。
: version 0 の場合は nameRecord 配列だけですが
: version 1 の場合はさらに langTag 配列も加わります。
022F3B6A-022F3B6B : 00,23 : count = 0x23。35 個の nameRecord があります。
022F3B6C-022F3B6D : 01,AA : storageOffset。文字列領域の場所。(table先頭からの位置)
022F3B6E- : : nameRecord[count] 配列
022F3D12- : : 文字列領域。(0x022F3B68 + 0x01AA = 0x22F3D12 です)
----------------- : ----------- : --------------------------------------
022F3B68-022F3B69 : 00,00 : version = 0。Naming table version 0 を意味します。
: version 0 の場合は nameRecord 配列だけですが
: version 1 の場合はさらに langTag 配列も加わります。
022F3B6A-022F3B6B : 00,23 : count = 0x23。35 個の nameRecord があります。
022F3B6C-022F3B6D : 01,AA : storageOffset。文字列領域の場所。(table先頭からの位置)
022F3B6E- : : nameRecord[count] 配列
022F3D12- : : 文字列領域。(0x022F3B68 + 0x01AA = 0x22F3D12 です)
Gekka さんのコードで実行した場合、NamingTable のインスタンスはこうなります。
.format = 0
.nameRecords.Count = 35
.langTagRecords.Count = 0
投稿者 魔界の仮面弁士 (社会人)
投稿日時
2021/11/13 12:51:51
> ★でエラーになります。
エラーになっているというより、エラーにしている箇所ですね。
より正確に言えば、「DSIG テーブルが存在しないときに、エラー扱いにしている」ものです。
DSIG とは Digital Signature。OpenType フォントのデジタル署名です。
署名の有無はこの後の解析に使用していないと思いますし、ここは単純に
If dsigTag <> &H44534947 AndAlso dsigTag <> 0 Then '🟨
へと変更すればよいと思います。
> 何か御存じでしたら、教えて頂きたいです。
フォント仕様については全く知りませんでしが、少し調べてみたらわかりました。
それぞれの処理の意味が分かれば、VBA でも VB.NET でも解析できますね。
構造仕様については下記を参照してみてください。
https://nazuna.sakura.ne.jp/wiki/index.php/TTC
https://docs.microsoft.com/en-us/typography/opentype/spec/otff
まずは C:\Windows\Fonts\mingliub.ttc をバイナリ エディターで開いてみます。
OpenType フォントの解析作業には、フォントの最上位テーブルのディレクトリ🔵である
TableDirectory を探ることが重要です。
フォントが 1 つしかない場合は、ファイルの先頭 0 バイト目から記されるようですが
複数のフォントを含むコレクションファイルの場合は、ファイルの先頭に TTCHeader と
いうものが置かれており、そこにそれぞれのフォントの TableDirectory の位置が記載されるとのこと。
ということで、まず大事なのは最初の 4 バイトでの識別ですが、
今回は TTC ヘッダー Version 2.0 がファイルの先頭に書かれていました。
そこから「3 つの TrueType フォントがこの 1 ファイルに含まれている」🟢と分かります。
つまり、Gekka.Text.Font.TrueType.TTC.Read(fontFile).Count も 3 になる想定。
エラーになっているというより、エラーにしている箇所ですね。
より正確に言えば、「DSIG テーブルが存在しないときに、エラー扱いにしている」ものです。
DSIG とは Digital Signature。OpenType フォントのデジタル署名です。
署名の有無はこの後の解析に使用していないと思いますし、ここは単純に
If dsigTag <> &H44534947 AndAlso dsigTag <> 0 Then '🟨
へと変更すればよいと思います。
> 何か御存じでしたら、教えて頂きたいです。
フォント仕様については全く知りませんでしが、少し調べてみたらわかりました。
それぞれの処理の意味が分かれば、VBA でも VB.NET でも解析できますね。
構造仕様については下記を参照してみてください。
https://nazuna.sakura.ne.jp/wiki/index.php/TTC
https://docs.microsoft.com/en-us/typography/opentype/spec/otff
まずは C:\Windows\Fonts\mingliub.ttc をバイナリ エディターで開いてみます。
OpenType フォントの解析作業には、フォントの最上位テーブルのディレクトリ🔵である
TableDirectory を探ることが重要です。
フォントが 1 つしかない場合は、ファイルの先頭 0 バイト目から記されるようですが
複数のフォントを含むコレクションファイルの場合は、ファイルの先頭に TTCHeader と
いうものが置かれており、そこにそれぞれのフォントの TableDirectory の位置が記載されるとのこと。
ということで、まず大事なのは最初の 4 バイトでの識別ですが、
今回は TTC ヘッダー Version 2.0 がファイルの先頭に書かれていました。
そこから「3 つの TrueType フォントがこの 1 ファイルに含まれている」🟢と分かります。
つまり、Gekka.Text.Font.TrueType.TTC.Read(fontFile).Count も 3 になる想定。
位置 : バイナリ : 説明
--------- : ------------ : --------------------------------------
0000-0003 : 74,74,63,66 : ttcTag = "ttcf"。TTC(True Type Collection)ヘッダー識別用の固定 ID です。
0004-0005 : 00,02 : majorVersion = 2。TTC ヘッダーの major version です。(1 または 2)
0006-0007 : 00,00 : minorVersion = 0。TTC ヘッダーの minor version です。
0008-000B : 00,00,00,03 : numFonts = 3。 3 個の TableDirectory 🔵 が含まれていることを意味します。
000C-000F : 00,00,00,24 : TableDirectory[0] が、0024 の位置から開始されます。(ファイル先頭を 0 とする位置)
0010-0013 : 00,00,01,50 : TableDirectory[1] が、0150 の位置から開始されます。
0014-0017 : 00,00,02,7C : TableDirectory[2] が、027C の位置から開始されます。
TTC ヘッダー 1.0 ならここまでですが、今回は TTC ヘッダー 2.0 なので
この後に DISG テーブルの情報が 12 バイト分続きます。
0018-001B : 00,00,00,00 : dsigTag = null。DSIG テーブルの有無を示すタグ🟨です。
: ここが 0x44534947 (String の "DSIG")であれが「存在する」
: ここが 0x00000000 であれば「存在しない」ということです。
: Gekka さんのコードでは、電子署名の無いファイルを解析エラーにしています。
001C-001F : 00,00,00,00 : dsigLength = 0。DSIG テーブルの長さを表します。
: ただし dsigTag = 0x44534947 の時は未使用(0x00000000)です。
0020-0023 : 00,00,00,00 : dsigOffset = 0。DSIG テーブルの位置を表します。(ファイル先頭を 0 とする位置)
: ただし dsigTag = 0x44534947 の時は未使用(0x00000000)です。
TTC ヘッダー 2.0 はここまでです。
ここからは TableDirectory[0] 🔵の内容です。
0024-0027 : 00,01,00,00 : version = 0x00010000。OpenType フォントのバージョン情報です。
: 0x4F54544F("OTTO") なら CFF/PostScript アウトラインを含む OpenType フォント
: 0x00010000 の場合は TrueType アウトラインを含む OpenType フォントです。
: Apple仕様の TrueType フォントである 0x74727565("true") や
: 0x74797031("typ1") は使うことができないようです。知らんけど。
0028-0029 : 00,12 : numTables = 0x12。つまり、18 個の TableRecord テーブルがあるということです。
002A-002B : 01,00 : searchRange = 0x100。「numTables 以下の最大の 2 の累乗値」を 16 倍した値です。
: numTables = 10 なら、2³≦numTables<2⁴ なので 2³*16 = 0x0030 が記録されます。
: numTables = 18 ゆえ、2⁴≦numTables<2⁵ なので 2⁴*16 = 0x0100 が記録されます。
: numTables = 32 なら、2⁵≦numTables<2⁶ なので 2⁵*16 = 0x0200 が記録されます。
002C-002D : 00,04 : entrySelector = 0x0004。「numTables 以下の最大の 2 の累乗値」の二進対数値です。
: numTables = 10 なら、Log₂(2³) となるため 3 が記録されます。
: numTables = 18 なら、Log₂(2⁴) となるため 4 が記録されます。
: numTables = 32 なら、Log₂(2⁵) となるため 5 が記録されます。
002E-002F : 00,20 : rangeShift = 0x0020。「numTables * 16 - searchRange」です。
: searchRange, entrySelector, rangeShift の値は、テーブル検索用の
: パラメータなので、解析時には使わなくても問題ありません。
0030-014F : (省略) : TableRecord [0..numTables] な配列データが続きます。
ここまでが TableDirectory[0] の内容です。残りは同様。
0150- は TableDirectory[1] 🔵で、テーブル数が 0x12 個の TrueType と記録されています。
0280- は TableDirectory[2] 🔵で、テーブル数が 0x12 個の TrueType と記録されています。
--------- : ------------ : --------------------------------------
0000-0003 : 74,74,63,66 : ttcTag = "ttcf"。TTC(True Type Collection)ヘッダー識別用の固定 ID です。
0004-0005 : 00,02 : majorVersion = 2。TTC ヘッダーの major version です。(1 または 2)
0006-0007 : 00,00 : minorVersion = 0。TTC ヘッダーの minor version です。
0008-000B : 00,00,00,03 : numFonts = 3。 3 個の TableDirectory 🔵 が含まれていることを意味します。
000C-000F : 00,00,00,24 : TableDirectory[0] が、0024 の位置から開始されます。(ファイル先頭を 0 とする位置)
0010-0013 : 00,00,01,50 : TableDirectory[1] が、0150 の位置から開始されます。
0014-0017 : 00,00,02,7C : TableDirectory[2] が、027C の位置から開始されます。
TTC ヘッダー 1.0 ならここまでですが、今回は TTC ヘッダー 2.0 なので
この後に DISG テーブルの情報が 12 バイト分続きます。
0018-001B : 00,00,00,00 : dsigTag = null。DSIG テーブルの有無を示すタグ🟨です。
: ここが 0x44534947 (String の "DSIG")であれが「存在する」
: ここが 0x00000000 であれば「存在しない」ということです。
: Gekka さんのコードでは、電子署名の無いファイルを解析エラーにしています。
001C-001F : 00,00,00,00 : dsigLength = 0。DSIG テーブルの長さを表します。
: ただし dsigTag = 0x44534947 の時は未使用(0x00000000)です。
0020-0023 : 00,00,00,00 : dsigOffset = 0。DSIG テーブルの位置を表します。(ファイル先頭を 0 とする位置)
: ただし dsigTag = 0x44534947 の時は未使用(0x00000000)です。
TTC ヘッダー 2.0 はここまでです。
ここからは TableDirectory[0] 🔵の内容です。
0024-0027 : 00,01,00,00 : version = 0x00010000。OpenType フォントのバージョン情報です。
: 0x4F54544F("OTTO") なら CFF/PostScript アウトラインを含む OpenType フォント
: 0x00010000 の場合は TrueType アウトラインを含む OpenType フォントです。
: Apple仕様の TrueType フォントである 0x74727565("true") や
: 0x74797031("typ1") は使うことができないようです。知らんけど。
0028-0029 : 00,12 : numTables = 0x12。つまり、18 個の TableRecord テーブルがあるということです。
002A-002B : 01,00 : searchRange = 0x100。「numTables 以下の最大の 2 の累乗値」を 16 倍した値です。
: numTables = 10 なら、2³≦numTables<2⁴ なので 2³*16 = 0x0030 が記録されます。
: numTables = 18 ゆえ、2⁴≦numTables<2⁵ なので 2⁴*16 = 0x0100 が記録されます。
: numTables = 32 なら、2⁵≦numTables<2⁶ なので 2⁵*16 = 0x0200 が記録されます。
002C-002D : 00,04 : entrySelector = 0x0004。「numTables 以下の最大の 2 の累乗値」の二進対数値です。
: numTables = 10 なら、Log₂(2³) となるため 3 が記録されます。
: numTables = 18 なら、Log₂(2⁴) となるため 4 が記録されます。
: numTables = 32 なら、Log₂(2⁵) となるため 5 が記録されます。
002E-002F : 00,20 : rangeShift = 0x0020。「numTables * 16 - searchRange」です。
: searchRange, entrySelector, rangeShift の値は、テーブル検索用の
: パラメータなので、解析時には使わなくても問題ありません。
0030-014F : (省略) : TableRecord [0..numTables] な配列データが続きます。
ここまでが TableDirectory[0] の内容です。残りは同様。
0150- は TableDirectory[1] 🔵で、テーブル数が 0x12 個の TrueType と記録されています。
0280- は TableDirectory[2] 🔵で、テーブル数が 0x12 個の TrueType と記録されています。
投稿者 snowmansnow (社会人)
投稿日時
2021/11/12 21:48:37
こんばんは魔界の仮面弁士様、るきお様、皆様
教えて頂いたGekka様のNamesを使って、
自分の環境のTTC、TTF調べてみました。(371個)
言語は、米国語、ドイツ語、中国語(繁体字)、韓国語をインストールしています。
ただ一つだけエラーになりました。
C:\Windows\Fonts\mingliub.ttc
MingLiU_HKSCS-ExtB 標準 繁体字
MingLiU-ExtB 標準 繁体字
PMingLiU-ExtB 標準 繁体字
Gekka様の
Public Sub Read(ByVal stream As System.IO.Stream)
stream.Seek(0, System.IO.SeekOrigin.Begin)
ttcTag = New Byte(4 - 1) {}
If stream.Read(ttcTag, 0, 4) <> 4 Then
Throw New System.IO.InvalidDataException()
End If
If Not (IsTTC) Then
offsetTables = New Offset32(1 - 1) {}
offsetTables(0) = New Offset32()
Else
majorVersion = stream.ReadUInt16BE()
minorVersion = stream.ReadUInt16BE()
numFonts = stream.ReadUInt32BE()
offsetTables = New Offset32(numFonts - 1) {}
With Nothing
Dim i As Integer = 0
For _F_2 As Integer = 0 To 1 Step 0
If Not (i < numFonts) Then
Exit For
End If
offsetTables(i) = New Offset32()
offsetTables(i).offset = stream.ReadUInt32BE()
i += 1
Next
End With
If majorVersion >= 2 Then
dsigTag = stream.ReadUInt32BE()
dsigLength = stream.ReadUInt32BE()
dsigOffset = stream.ReadUInt32BE()
If dsigTag <> &H44534947 Then
★ Throw New System.IO.InvalidDataException()
End If
End If
End If
End Sub
★でエラーになります。
漢字圏でも中国語はダメなのでしょうか?
何か御存じでしたら、教えて頂きたいです。
投稿者 snowmansnow (社会人)
投稿日時
2021/11/10 20:14:57
こんばんは、魔界の仮面弁士様、るきお様
お返事ありがとうございます
>> Fontには、名前とファミリーとファイルがあると思いますが、
>……?
は、素人話すぎてわかりずらかったと思います。
コントロールパネルのフォントで、表示形式を詳細で開いて
右ボタンでチェックできる、詳細で見せる各欄の中に
名前とファミリ(ー)と(フォント)ファイルがあったので、
それを表現したかったです。
そのフォント一覧を見ると多くのWEBでは、フォントは、
①C:\windows\Fonts\以下にあると書いてあるものが多いと思いますが
②C:ユーザー\windows\Fonts\以下もあったり、(自分でインストールしたもの?)
③年賀状ソフトの使用で増えたと思われるものもあったりして、(全く別のフォルダ)
仕方ないので、
①と②のフォルダ中でフォントファイルを取得して、③の取得はあきらめて、
ファミリを、そのファイルを元にWEBのフォント(名)の取得のコードを参考に、取得は出来るようになりました。
今回、御教授頂いたもので、名前(いっぱい)は取得できるようになりましたが、
嬉しい悲鳴で、いっぱいあって、どれが、何の為にあって、どのように使うかが
新しい疑問(高度すぎ?)として湧きました・・・
御教授頂いたwebを読んで勉強してみます。
大変大変ありがたく、勉強もでき、嬉しいです。
また、他の疑問が生じましたら宜しくお願い致します。
投稿者 魔界の仮面弁士 (社会人)
投稿日時
2021/11/10 01:27:12
> Fontには、名前とファミリーとファイルがあると思いますが、
……?
仰っている意味が良く分かりませんが、Naming table のことでしょうか。
https://docs.microsoft.com/en-us/typography/opentype/spec/name
https://docs.microsoft.com/en-us/typography/opentype/spec/namesmp
Gekka さんのコードだと、Names プロパティから得られる List(Of Name) コレクションにて受け取れます。
……?
仰っている意味が良く分かりませんが、Naming table のことでしょうか。
Name ID = 1 → Font Family name
Name ID = 2 → Font Subfamily name
Name ID = 4 → Full font name
Name ID = 16 → Typographic family name
Name ID = 17 → Typographic Subfamily name
Name ID = 2 → Font Subfamily name
Name ID = 4 → Full font name
Name ID = 16 → Typographic family name
Name ID = 17 → Typographic Subfamily name
https://docs.microsoft.com/en-us/typography/opentype/spec/name
https://docs.microsoft.com/en-us/typography/opentype/spec/namesmp
Gekka さんのコードだと、Names プロパティから得られる List(Of Name) コレクションにて受け取れます。
Public Class Form1
Private Sub Button1_Click(sender As Object, e As EventArgs) Handles Button1.Click
ListBox1.BeginUpdate()
ListBox1.Items.Clear()
Dim fontFile As String
'fontFile = "C:\Windows\Fonts\ipamjm.ttf"
'fontFile = "C:\Windows\Fonts\arial.ttf"
fontFile = "C:\Windows\Fonts\meiryo.ttc"
For Each ttf In Gekka.Text.Font.TrueType.TTC.Read(fontFile)
ListBox1.Items.Add("-----------")
For Each nm In ttf.Names
ListBox1.Items.Add($"Id={nm.ID:d}({nm.ID:G})")
ListBox1.Items.Add($"LanguageID={nm.LanguageID}")
ListBox1.Items.Add($"Language={nm.Language}")
ListBox1.Items.Add($"Text={nm.Text}")
ListBox1.Items.Add("")
Next
Next
ListBox1.EndUpdate()
End Sub
End Class
投稿者 snowmansnow (社会人)
投稿日時
2021/11/9 21:45:26
こんばんは、魔界の仮面弁士様、るきお様
サロゲートペアも御教授通り、コードポイントを入れる形で動かせました。
でも、Gekka様のNamesが取得できませんでした。
Fontには、名前とファミリーとファイルがあると思いますが、
ファミリーとファイルは、御教授頂いたクラスライブラリのやり方でやっと手に入れられましたが、
名前は、自力では無理でした。
Gekka様のNamesが名前だと思っていますが、取得の御教授お願いしたいです。
投稿者 snowmansnow (社会人)
投稿日時
2021/10/10 11:00:28
こんにちは、魔界の仮面弁士様、るきお様
熱が平熱になったり、上がったり一進一退を繰り返しています
>②TTC クラスの FindFont メソッドは、フォント名から *.ttf/*.ttc を検索するものです。
> うまく検索できない場合があったので、その場合には
> Return New >System.IO.FileInfo("C:\Users\Y2\AppData\Local\Microsoft\Windows\Fonts\ipamjm.ttf")
> のように固定パスで FileInfo を返すようにすれば、とりあえず先に進むかと。
上記の話を事前に書いておいて頂いていたので、修正して無事動きました!!
るきお様のWEBも頼りになります!!
大変ありがとうございます
>③肝となるのが Public Shared Function FindISV なわけですが、元のコードでは
> ByVal targetChar As Char な引数を受け取り、CUInt(AscW(targetChar)) を渡しています。
> これだと、サロゲートペアを処理できないので、メソッドを Overloads して、>? ByVal targetChar As >UInteger を受け取るメソッドをもう一つ用意してみてください。
> そして、このメソッドに "𩸽" を渡すのではなく、そのコードポイントとなる
> &H29E3DUI を引き渡すようにします。
オーバーロードはできるかどうかわかりませんが、別関数にしたら出来るかも?と思っております
まだ体調不調なので、ゆっくりがんばってみます
投稿者 魔界の仮面弁士 (社会人)
投稿日時
2021/10/9 19:48:10
> Nugetでも探せず、何を参照したらよいか分かりませんでした。
nuget は特に不要ですよ。
> Gekka さんのソースもVB.NETで試してみたのですが、
プロジェクトのプロパティで、ルート名前空間は何に設定されていますか?
もしも「ルート名前空間」という言葉を御存知ない場合は、
VB中学校の
初級講座 第51回 クラスライブラリの作成 「6.名前空間」
初級講座[改訂版] 第31回 クラスライブラリ 「5.名前空間」
などで触れられています。
> Imports Gekka.Text.Font.TrueType.CMAP
> Imports Gekka.Text.Font.TrueType.Naming
> Imports Gekka.Text.Font.TrueType.Common
そのコードのすぐ下の行から
「Namespace Gekka.Text.Font.TrueType」
で始まる名前空間がありましたよね。
その名前空間の中に、上記 3 つの名前空間
🔶CMAP ◆Naming 🔹Common
が定義されているはずです。
見通せるように、名前空間と型定義の部分を抜粋しておきます。
>> Namespace Gekka.Text.Font.TrueType
>> Public Class TTC
>> Friend Class TTCHeader
>> Public Enum TTFDataReadTypes As ULong
>> Public Class TTF
>> Namespace Common '←🔹
>> MustInherit Class OffsetBase
>> Friend Class Offset16
>> Friend Class Offset32
>> Friend Class Range
>> Friend Enum PlatformID As UShort
>> Friend Enum WindowsEncodingIDs
>> Friend Enum ISOEncodingIDs
>> End Namespace
>> Friend Class FontHeader
>> Friend Class FontHeader
>> Friend Class TableRecord
>> Namespace CMAP '←🔶
>> Friend Class CmapTable
>> Friend Class EncodingRecord
>> Friend Class UnicodeVariationSequences
>> Friend Class VariationSelector
>> Friend Class DefaultUVSTable
>> Friend Class UnicodeRange
>> Friend Class NonDefaultUVSTable
>> Friend Class UVSMapping
>> End Namespace
>> Namespace Naming '←◆
>> Friend Class NamingTable
>> Friend Class LangTagRecord
>> Friend Class NameRecord
>> Public Enum NameIDs As UShort
>> Public Class Name
>> End Namespace
>> Module BigEndianExtension
>> End Namespace
> 「Imports 」の謎を教えて頂きたいです。
名前空間の指定がうまくいかないのであれば、
①ひとまずルート名前空間を空にしてみる
ことを試してみてください。
あるいは、ルート名前空間を任意のものとしたまま
②「Namespace Gekka.Text.Font.TrueType」のところを
「Namespace Global.Gekka.Text.Font.TrueType」にしてみる
という手法もあります。(グローバル名前空間は VB2010 以降の機能です)
https://docs.microsoft.com/ja-jp/dotnet/visual-basic/programming-guide/program-structure/namespaces
nuget は特に不要ですよ。
> Gekka さんのソースもVB.NETで試してみたのですが、
プロジェクトのプロパティで、ルート名前空間は何に設定されていますか?
もしも「ルート名前空間」という言葉を御存知ない場合は、
VB中学校の
初級講座 第51回 クラスライブラリの作成 「6.名前空間」
初級講座[改訂版] 第31回 クラスライブラリ 「5.名前空間」
などで触れられています。
> Imports Gekka.Text.Font.TrueType.CMAP
> Imports Gekka.Text.Font.TrueType.Naming
> Imports Gekka.Text.Font.TrueType.Common
そのコードのすぐ下の行から
「Namespace Gekka.Text.Font.TrueType」
で始まる名前空間がありましたよね。
その名前空間の中に、上記 3 つの名前空間
🔶CMAP ◆Naming 🔹Common
が定義されているはずです。
見通せるように、名前空間と型定義の部分を抜粋しておきます。
>> Namespace Gekka.Text.Font.TrueType
>> Public Class TTC
>> Friend Class TTCHeader
>> Public Enum TTFDataReadTypes As ULong
>> Public Class TTF
>> Namespace Common '←🔹
>> MustInherit Class OffsetBase
>> Friend Class Offset16
>> Friend Class Offset32
>> Friend Class Range
>> Friend Enum PlatformID As UShort
>> Friend Enum WindowsEncodingIDs
>> Friend Enum ISOEncodingIDs
>> End Namespace
>> Friend Class FontHeader
>> Friend Class FontHeader
>> Friend Class TableRecord
>> Namespace CMAP '←🔶
>> Friend Class CmapTable
>> Friend Class EncodingRecord
>> Friend Class UnicodeVariationSequences
>> Friend Class VariationSelector
>> Friend Class DefaultUVSTable
>> Friend Class UnicodeRange
>> Friend Class NonDefaultUVSTable
>> Friend Class UVSMapping
>> End Namespace
>> Namespace Naming '←◆
>> Friend Class NamingTable
>> Friend Class LangTagRecord
>> Friend Class NameRecord
>> Public Enum NameIDs As UShort
>> Public Class Name
>> End Namespace
>> Module BigEndianExtension
>> End Namespace
> 「Imports 」の謎を教えて頂きたいです。
名前空間の指定がうまくいかないのであれば、
①ひとまずルート名前空間を空にしてみる
ことを試してみてください。
あるいは、ルート名前空間を任意のものとしたまま
②「Namespace Gekka.Text.Font.TrueType」のところを
「Namespace Global.Gekka.Text.Font.TrueType」にしてみる
という手法もあります。(グローバル名前空間は VB2010 以降の機能です)
https://docs.microsoft.com/ja-jp/dotnet/visual-basic/programming-guide/program-structure/namespaces
投稿者 snowmansnow (社会人)
投稿日時
2021/10/9 18:32:53
こんばんは、魔界の仮面弁士様、るきお様
木曜の深夜から高熱が続き、やっと平熱になって来ました・・・
>> Public Function ToUTF16
> は、言語が何なのか?試せませんでした・・・
.>Visual Basic 14.0 以降向けのコードです。
試し方が悪かったのか、VB.NETで動かせませんでした・・・
また動かしてみます
>> Gekka さんのコードを参考にして、「𩸽」の文字を試してみました。
> これが、知りたかった話なのですが、
.>Gekka さんのソース、ほぼそのままですよ。
Gekka さんのソースもVB.NETで試してみたのですが、
Imports Gekka.Text.Font.TrueType.CMAP
Imports Gekka.Text.Font.TrueType.Naming
Imports Gekka.Text.Font.TrueType.Common
がNugetでも探せず、何を参照したらよいか分かりませんでした。
他も赤波線が出て困ってましたが、がんばってみます。
「Imports 」の謎を教えて頂きたいです。
何回も申し訳ございません。
投稿者 魔界の仮面弁士 (社会人)
投稿日時
2021/10/7 23:06:29
>> Public Function ToUTF16
> は、言語が何なのか?試せませんでした・・・
失礼いたしました。
Visual Basic 14.0 以降向けのコードです。
以降向けのコードです。
NameOf 演算子が使われていることから、VB2015 以上が必要です。
とはいえ NameOf(codePage) は、文字列 "codePage" と完全に同義なので、
VB2013 以下の場合は、文字列にそのまま置き換えてください。
NameOf の事を知らない場合でも、Throw ステートメントが存在することや、
『If codePage < 0 OrElse &H10FFFF < codePage Then』の行を見ることで、
少なくとも VB.NET であることは、おそらく予想いただけていたものと思います。
VBA や VBScript では、Or はあっても OrElse はありませんからね。
さらに言えば、Function の戻り値の型が『As UShort()』であったことから、
最初の一行だけ見ても、少なくとも VB2005 以上が対象だと判定することができます。
ちなみに、VB.NET 2002/2003 でも動かそうとするのであれば、
As UShort を As UInt16 と書き換えて、CUShort(x) を UInt16.Parse(x) にしたうえで、
最後の『Return {us, ls}』は、『Return New UInt32() {us, ls}』で置き換えます。
>> Gekka さんのコードを参考にして、「𩸽」の文字を試してみました。
> これが、知りたかった話なのですが、
Gekka さんのソース、ほぼそのままですよ。
やっていることは、フォントファイルのバイナリを解析しているだけなので、
ロジック的には、VBA でも実装可能です。
> これを導いたコードは、御教授いただけないでしょうか?
コード全文は長いので省きますが、
①Option Strict On 対応にするために、結構な手直しが必要でした。
修正箇所が多いので仔細は省略しますが、
Option Strict Off であれば、ほぼそのまま動くかもしれません。
②TTC クラスの FindFont メソッドは、フォント名から *.ttf/*.ttc を検索するものです。
うまく検索できない場合があったので、その場合には
Return New System.IO.FileInfo("C:\Users\Y2\AppData\Local\Microsoft\Windows\Fonts\ipamjm.ttf")
のように固定パスで FileInfo を返すようにすれば、とりあえず先に進むかと。
③肝となるのが Public Shared Function FindISV なわけですが、元のコードでは
ByVal targetChar As Char な引数を受け取り、CUInt(AscW(targetChar)) を渡しています。
これだと、サロゲートペアを処理できないので、メソッドを Overloads して、
ByVal targetChar As UInteger を受け取るメソッドをもう一つ用意してみてください。
そして、このメソッドに "𩸽" を渡すのではなく、そのコードポイントとなる
&H29E3DUI を引き渡すようにします。
ちなみに、フォームのタイトルバーに書いた情報は、.ttf ファイルのプロパティを見て
書き写したものですが、この情報をプログラムから取得したいのであれば、
TTF クラスの Names プロパティから取得できます。(Gekka さんのコードでは
TTF クラスの IVSMap プロパティしか参照していませんが、Names も読み取れるように実装されています)
> は、言語が何なのか?試せませんでした・・・
失礼いたしました。
Visual Basic 14.0
NameOf 演算子が使われていることから、VB2015 以上が必要です。
とはいえ NameOf(codePage) は、文字列 "codePage" と完全に同義なので、
VB2013 以下の場合は、文字列にそのまま置き換えてください。
NameOf の事を知らない場合でも、Throw ステートメントが存在することや、
『If codePage < 0 OrElse &H10FFFF < codePage Then』の行を見ることで、
少なくとも VB.NET であることは、おそらく予想いただけていたものと思います。
VBA や VBScript では、Or はあっても OrElse はありませんからね。
さらに言えば、Function の戻り値の型が『As UShort()』であったことから、
最初の一行だけ見ても、少なくとも VB2005 以上が対象だと判定することができます。
ちなみに、VB.NET 2002/2003 でも動かそうとするのであれば、
As UShort を As UInt16 と書き換えて、CUShort(x) を UInt16.Parse(x) にしたうえで、
最後の『Return {us, ls}』は、『Return New UInt32() {us, ls}』で置き換えます。
>> Gekka さんのコードを参考にして、「𩸽」の文字を試してみました。
> これが、知りたかった話なのですが、
Gekka さんのソース、ほぼそのままですよ。
やっていることは、フォントファイルのバイナリを解析しているだけなので、
ロジック的には、VBA でも実装可能です。
> これを導いたコードは、御教授いただけないでしょうか?
コード全文は長いので省きますが、
①Option Strict On 対応にするために、結構な手直しが必要でした。
修正箇所が多いので仔細は省略しますが、
Option Strict Off であれば、ほぼそのまま動くかもしれません。
②TTC クラスの FindFont メソッドは、フォント名から *.ttf/*.ttc を検索するものです。
うまく検索できない場合があったので、その場合には
Return New System.IO.FileInfo("C:\Users\Y2\AppData\Local\Microsoft\Windows\Fonts\ipamjm.ttf")
のように固定パスで FileInfo を返すようにすれば、とりあえず先に進むかと。
③肝となるのが Public Shared Function FindISV なわけですが、元のコードでは
ByVal targetChar As Char な引数を受け取り、CUInt(AscW(targetChar)) を渡しています。
これだと、サロゲートペアを処理できないので、メソッドを Overloads して、
ByVal targetChar As UInteger を受け取るメソッドをもう一つ用意してみてください。
そして、このメソッドに "𩸽" を渡すのではなく、そのコードポイントとなる
&H29E3DUI を引き渡すようにします。
ちなみに、フォームのタイトルバーに書いた情報は、.ttf ファイルのプロパティを見て
書き写したものですが、この情報をプログラムから取得したいのであれば、
TTF クラスの Names プロパティから取得できます。(Gekka さんのコードでは
TTF クラスの IVSMap プロパティしか参照していませんが、Names も読み取れるように実装されています)
投稿者 snowmansnow (社会人)
投稿日時
2021/10/7 21:51:48
こんばんは、魔界の仮面弁士様、るきお様、
先週、今週と体調不良なのと、
皆さんから御教授頂いた内容がてんこ盛りで、時間がかかりました!
>第0面~第16面
は、
https://ja.wikipedia.org/wiki/Unicode%E4%B8%80%E8%A6%A7%E8%A1%A8
https://ja.wikipedia.org/wiki/%E9%9D%A2_(%E6%96%87%E5%AD%97%E3%82%B3%E3%83%BC%E3%83%89)
IMEパッド 文字カテゴリ
などを見て、理解できました。
>ParamArray試しました
とてもスマートで美しかったです。
>たとえば「á」であれば
>UTF-16では 4 バイト(0061 0301) で表現されます。
UTF-16が2つなのでサロゲートの1つだと思ってました。
UTF-16がD800〜E000のでないのでサロゲートでないのがわかりました。
(U+010000 〜 U+10FFFF の範囲でないので、サロゲートでないのがわかりました。)
>Public Function ToUTF16
は、言語が何なのか?試せませんでした・・・
試して、下部の説明も理解したいです。
>① [U+8ECA] "基底文字" (CJK UNIFIED IDEOGRAPH-8ECA)
>② [U+8ECA][U+FE00] "標準異体字" (CJK COMPATIBILITY IDEOGRAPH-F902)
>③ [U+8ECA][U+E0100] "Adobe-Japan1" (CID+2306)
②uni(36554,65024)
③uni(36554,56128,56577)
で確認いたしました
でもエクセルだと、②は結合してない?中心寄せで真ん中にこないです・・・
>対応フォントまでは調べていないですが、IVS(異体字シーケンス)の登録はこんな感じでした。
>のVS~
は何かな?と思いましたが、
https://p--q.blogspot.com/2018/03/libreoffice5151unicodevariation-selector.html
で、
SVSにはU+FE00からU+FE0Fまでの4桁の16進数の16個がVS1からVS16として割り当てられています。
IVSにはU+E0100からU+E01EFまでの5桁の16進数の240個がVS17からVS256として割り当てられています。
という説明で理解できました。
>Public は「マクロの表示」に現れますが、Private は表示されません。
ありがとうございます。ダミー?変数は、いらなくなると思います。
>Gekka さんのコードを参考にして、「𩸽」の文字を試してみました。
これが、知りたかった話なのですが、
これを導いたコードは、御教授いただけないでしょうか?
Glyphのindexが何なのか、非常に興味があります。
連続してるのか、飛び飛びなのか、𩸽以外も知りたいです。
投稿者 魔界の仮面弁士 (社会人)
投稿日時
2021/10/7 10:57:48
> 2の異体字セレクタは IVS の [VS1]、
> 3の異体字セレクタは IVS の [VS17] です。
おぉっと。
『2の異体字セレクタは SVS の [VS1]』の書き間違いです。
> VBAで、マクロの表示をすると、何でも表示されてしまうので、
> subに何か、変数を渡す形にすると、表示されないための対策の癖でした。
Public / Friend / Private の修飾子を付けてみるのはどうでしょうか?
Public は「マクロの表示」に現れますが、Private は表示されません。
> UVS マップでは、Unicode値として uint32 あるいは uint24 を扱います。
> .NET の Char 型は 16 ビットなので、U+10000 以降の文字を扱う場合は、
> 検索前に Unicode コードポイントに変換しておいてください。
『BMP (U+0000~U+FFFF) および第1~16面(U+10000~U+10FFFF)の任意の一文字』を
表すデータ型として、System.Text.Rune 構造体を使うこともできます。
(.NET Framework 環境では使えませんが)
Rune 構造体を使って "𩸽" を 0x29E3D に変換する例。
[C#]
>> 𩸽は、29E3D,E0100~29E3D,E0104
> 以前 Gekka さんが、フォントファイルの cmap Format 14 から
> 異体字セレクタを列挙するコードを MSDN Forum に投稿されていました。
Gekka さんのコードを参考にして、「𩸽」の文字を試してみました。
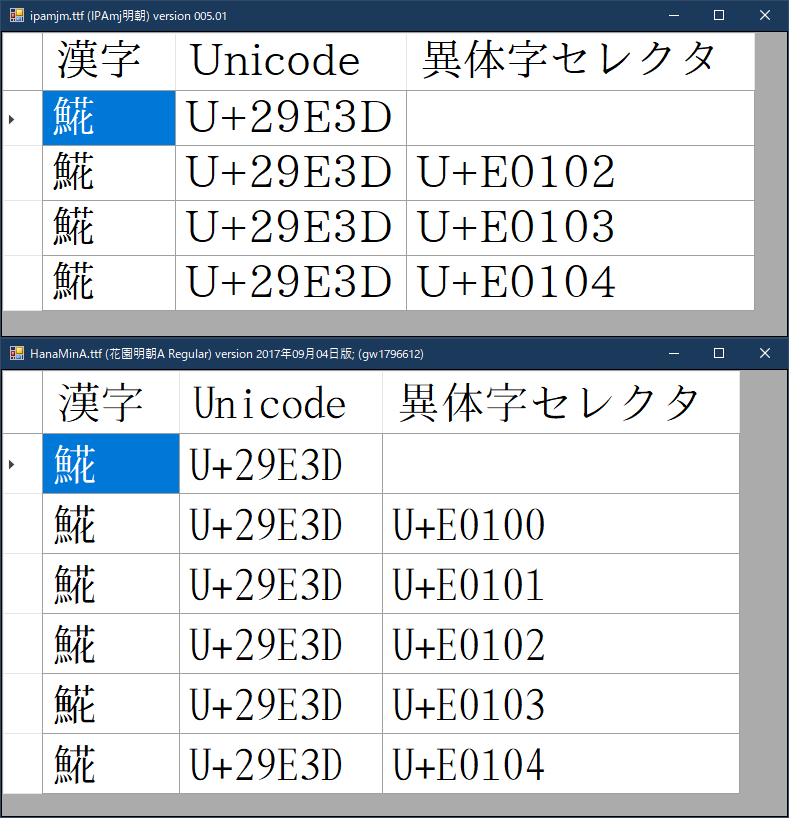
IPAmj明朝 には、Adobe-Japan1 コレクションの異体字が含まれていませんが
花園明朝A には、Adobe-Japan1 コレクションと Moji_Joho コレクションが含まれていました。
> 3の異体字セレクタは IVS の [VS17] です。
おぉっと。
『2の異体字セレクタは SVS の [VS1]』の書き間違いです。
> VBAで、マクロの表示をすると、何でも表示されてしまうので、
> subに何か、変数を渡す形にすると、表示されないための対策の癖でした。
Public / Friend / Private の修飾子を付けてみるのはどうでしょうか?
Public は「マクロの表示」に現れますが、Private は表示されません。
Public Sub MAIN()
End Sub
Private Sub IVDINI()
End Sub> UVS マップでは、Unicode値として uint32 あるいは uint24 を扱います。
> .NET の Char 型は 16 ビットなので、U+10000 以降の文字を扱う場合は、
> 検索前に Unicode コードポイントに変換しておいてください。
『BMP (U+0000~U+FFFF) および第1~16面(U+10000~U+10FFFF)の任意の一文字』を
表すデータ型として、System.Text.Rune 構造体を使うこともできます。
(.NET Framework 環境では使えませんが)
Rune 構造体を使って "𩸽" を 0x29E3D に変換する例。
[C#]
if (System.Text.Rune.TryGetRuneAt("𩸽", 0, out System.Text.Rune rune))
{
// U+00029E3D
Console.WriteLine($"U+{rune.Value:X8}");
// D867,DE3D
char[] utf16 = new char[2]; // 格納するために十分なバッファ
int n = rune.EncodeToUtf16(utf16);
Console.WriteLine(string.Join(',', utf16.Take(n).Select(c => $"{(int)c:X4}")));
// f0 a9 b8 bd
byte[] utf8 = new byte[4]; // 格納するために十分なバッファ
int m = rune.EncodeToUtf8(utf8);
Console.WriteLine(string.Join(' ', utf8.Take(m).Select(b => $"{b:x2}")));
}>> 𩸽は、29E3D,E0100~29E3D,E0104
> 以前 Gekka さんが、フォントファイルの cmap Format 14 から
> 異体字セレクタを列挙するコードを MSDN Forum に投稿されていました。
Gekka さんのコードを参考にして、「𩸽」の文字を試してみました。
IPAmj明朝 には、Adobe-Japan1 コレクションの異体字が含まれていませんが
花園明朝A には、Adobe-Japan1 コレクションと Moji_Joho コレクションが含まれていました。
投稿者 魔界の仮面弁士 (社会人)
投稿日時
2021/10/6 10:46:33
> コードポイント?が2つ?の(あ)異体字と(い)サロゲートペア異体字のフォント内のグリフ?の確認方法を
> 教えて頂きたかったでした。
(あ)異体字というのは SVS のことで、
(い)サロゲートペア異体字とは IVS のことでしょうか?
※ SVS はサロゲートペアを必要とせず、基本多言語面のみで表せるので。
たとえば「車」の異体字割り当てを見ると、下記の 3 つがあります。
3は UTF-16 だとサロゲートペアが必要ですが、1と2はサロゲートペアを必要としません。
この基底文字は基本多言語面(BMP)にあります。
2の異体字セレクタは IVS の [VS1]、3の異体字セレクタは IVS の [VS17] です。
>IPAmj明朝で𩸽は、コードポイント171581ですが、取得できるグリフ番号は、55556ですが、
「文字コード」というよりは、「フォント」の話になりますね。
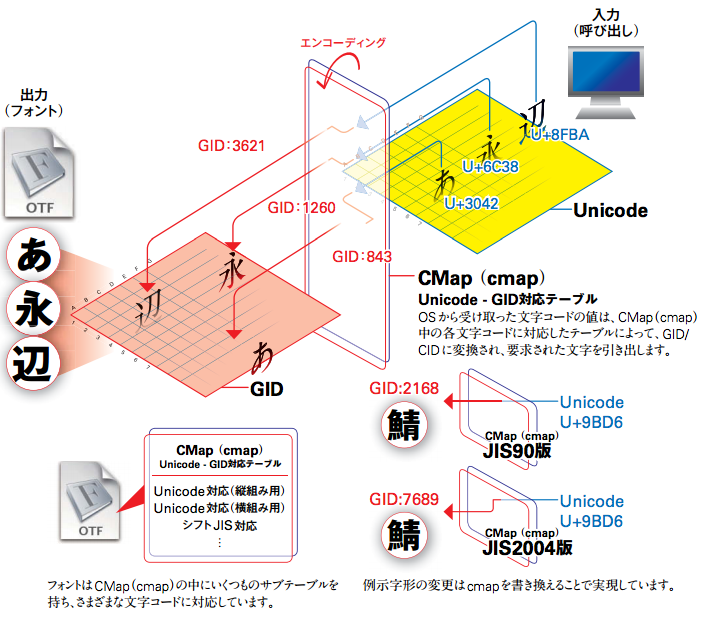
グリフIDへの変換には、cmap (≒CMap) サブテーブルが使われます。
> CharacterToGlyphMapで取得されるグリフのidで表示される文字が、
> 異体字なら、1個なのか、2個以上なのかを確認したかった、ものです。
Unicode 第0面 (BMP) の U+0000~U+FFFF は Format 4 を参照します。
Unicode 第1面~第16面の U+10000~U+10FFFF は、Format 12 を参照します。
異体字セレクタ(UVS) は Format 14 を参照します。
Format 0: Byte encoding table
Format 2: High-byte mapping through table
Format 4: Segment mapping to delta values
Format 6: Trimmed table mapping
Format 8: mixed 16-bit and 32-bit coverage
Format 10: Trimmed array
Format 12: Segmented coverage
Format 13: Many-to-one range mappings
Format 14: Unicode Variation Sequences
https://aznote.jakou.com/prog/opentype/08_cmap.html
https://www.usefullcode.net/2016/04/11_cmap_from_font_file.html
https://docs.microsoft.com/ja-jp/typography/opentype/spec/cmap?WT.mc_id=DT-MVP-8907#format-14-unicode-variation-sequences
https://developer.apple.com/fonts/TrueType-Reference-Manual/
上記 Azel さんのサイトにも書かれていますが、cmap Format 14 は、
platformID = 0(Unicode) かつ encodingID = 5(Unicode Variation Sequences) が必須です。
UVS マップでは、Unicode値として uint32 あるいは uint24 を扱います。
.NET の Char 型は 16 ビットなので、U+10000 以降の文字を扱う場合は、
検索前に Unicode コードポイントに変換しておいてください。
以前 Gekka さんが、フォントファイルの cmap Format 14 から
異体字セレクタを列挙するコードを MSDN Forum に投稿されていました。
検索条件が Char になっているので、BMP 範囲の基底文字しか拾えませんが
考え方の参考になるかと思います。
https://social.msdn.microsoft.com/Forums/ja-JP/24b83554-2b0b-43ea-a375-39e7b989a571/30064203072338312398199683523912398209861237526041124342594512?forum=vbgeneralja
> 𩸽は、29E3D,E0100~29E3D,E0104
CJK統合漢字拡張漢字「𩸽」の基底文字は [U+29E3D] ですね。(CJK UNIFIED IDEOGRAPH-29E3D)
Unicode 第2面(SIP; 追加漢字面)なので、UTF-16 ではサロゲートペアの範囲。
対応フォントまでは調べていないですが、IVS(異体字シーケンス)の登録はこんな感じでした。
𩸽 [U+29E3D] → 𩸽
𩸽 [U+29E3D], VS17 [U+E0100] → 𩸽󠄀 (Adobe-Japan1: CID+20315)
𩸽 [U+29E3D], VS18 [U+E0101] → 𩸽󠄁 (Adobe-Japan1: CID+15437)
𩸽 [U+29E3D], VS19 [U+E0102] → 𩸽󠄂 (文字情報基盤: MJ055217 ; 汎用電子: JD9344 ; 住基ネット統一文字: J+ABBC)
𩸽 [U+29E3D], VS20 [U+E0103] → 𩸽󠄃 (文字情報基盤: MJ055216 ; 汎用電子: KS523690; 戸籍統一文字: 523690)
𩸽 [U+29E3D], VS21 [U+E0104] → 𩸽󠄄 (文字情報基盤: MJ055218 ; 住基ネット統一文字: J+C01A)
> 教えて頂きたかったでした。
(あ)異体字というのは SVS のことで、
(い)サロゲートペア異体字とは IVS のことでしょうか?
※ SVS はサロゲートペアを必要とせず、基本多言語面のみで表せるので。
たとえば「車」の異体字割り当てを見ると、下記の 3 つがあります。
3は UTF-16 だとサロゲートペアが必要ですが、1と2はサロゲートペアを必要としません。
① [U+8ECA] "基底文字" (CJK UNIFIED IDEOGRAPH-8ECA)
② [U+8ECA][U+FE00] "標準異体字" (CJK COMPATIBILITY IDEOGRAPH-F902)
③ [U+8ECA][U+E0100] "Adobe-Japan1" (CID+2306)
② [U+8ECA][U+FE00] "標準異体字" (CJK COMPATIBILITY IDEOGRAPH-F902)
③ [U+8ECA][U+E0100] "Adobe-Japan1" (CID+2306)
この基底文字は基本多言語面(BMP)にあります。
2の異体字セレクタは IVS の [VS1]、3の異体字セレクタは IVS の [VS17] です。
>IPAmj明朝で𩸽は、コードポイント171581ですが、取得できるグリフ番号は、55556ですが、
「文字コード」というよりは、「フォント」の話になりますね。
グリフIDへの変換には、cmap (≒CMap) サブテーブルが使われます。
> CharacterToGlyphMapで取得されるグリフのidで表示される文字が、
> 異体字なら、1個なのか、2個以上なのかを確認したかった、ものです。
Unicode 第0面 (BMP) の U+0000~U+FFFF は Format 4 を参照します。
Unicode 第1面~第16面の U+10000~U+10FFFF は、Format 12 を参照します。
異体字セレクタ(UVS) は Format 14 を参照します。
Format 0: Byte encoding table
Format 2: High-byte mapping through table
Format 4: Segment mapping to delta values
Format 6: Trimmed table mapping
Format 8: mixed 16-bit and 32-bit coverage
Format 10: Trimmed array
Format 12: Segmented coverage
Format 13: Many-to-one range mappings
Format 14: Unicode Variation Sequences
https://aznote.jakou.com/prog/opentype/08_cmap.html
https://www.usefullcode.net/2016/04/11_cmap_from_font_file.html
https://docs.microsoft.com/ja-jp/typography/opentype/spec/cmap?WT.mc_id=DT-MVP-8907#format-14-unicode-variation-sequences
https://developer.apple.com/fonts/TrueType-Reference-Manual/
上記 Azel さんのサイトにも書かれていますが、cmap Format 14 は、
platformID = 0(Unicode) かつ encodingID = 5(Unicode Variation Sequences) が必須です。
UVS マップでは、Unicode値として uint32 あるいは uint24 を扱います。
.NET の Char 型は 16 ビットなので、U+10000 以降の文字を扱う場合は、
検索前に Unicode コードポイントに変換しておいてください。
以前 Gekka さんが、フォントファイルの cmap Format 14 から
異体字セレクタを列挙するコードを MSDN Forum に投稿されていました。
検索条件が Char になっているので、BMP 範囲の基底文字しか拾えませんが
考え方の参考になるかと思います。
https://social.msdn.microsoft.com/Forums/ja-JP/24b83554-2b0b-43ea-a375-39e7b989a571/30064203072338312398199683523912398209861237526041124342594512?forum=vbgeneralja
> 𩸽は、29E3D,E0100~29E3D,E0104
CJK統合漢字拡張漢字「𩸽」の基底文字は [U+29E3D] ですね。(CJK UNIFIED IDEOGRAPH-29E3D)
Unicode 第2面(SIP; 追加漢字面)なので、UTF-16 ではサロゲートペアの範囲。
対応フォントまでは調べていないですが、IVS(異体字シーケンス)の登録はこんな感じでした。
𩸽 [U+29E3D] → 𩸽
𩸽 [U+29E3D], VS17 [U+E0100] → 𩸽󠄀 (Adobe-Japan1: CID+20315)
𩸽 [U+29E3D], VS18 [U+E0101] → 𩸽󠄁 (Adobe-Japan1: CID+15437)
𩸽 [U+29E3D], VS19 [U+E0102] → 𩸽󠄂 (文字情報基盤: MJ055217 ; 汎用電子: JD9344 ; 住基ネット統一文字: J+ABBC)
𩸽 [U+29E3D], VS20 [U+E0103] → 𩸽󠄃 (文字情報基盤: MJ055216 ; 汎用電子: KS523690; 戸籍統一文字: 523690)
𩸽 [U+29E3D], VS21 [U+E0104] → 𩸽󠄄 (文字情報基盤: MJ055218 ; 住基ネット統一文字: J+C01A)
投稿者 (削除されました) ()
投稿日時
2021/10/6 10:43:25
(削除されました)
投稿者 るきお (社会人)
投稿日時
2021/10/5 20:15:00
>るきおさん:
>> If cp1 <= 65535 Then
>> Debug.WriteLine("鯖はUnicode第1面にあります。")
>第1面ではなく、第0面ですよね。
その通りですね。間違いました。
ご指摘ありがとうございます。
>> If cp1 <= 65535 Then
>> Debug.WriteLine("鯖はUnicode第1面にあります。")
>第1面ではなく、第0面ですよね。
その通りですね。間違いました。
ご指摘ありがとうございます。
投稿者 魔界の仮面弁士 (社会人)
投稿日時
2021/10/5 16:25:42
> VB4 (32bit) が扱える Unicode バージョンは 3.0 であり
済みません! この部分、大嘘でした。
VB4 が Unicode 3.0 を扱えるというのは間違いです。
🔹VB4 が扱える範囲は BMP(基本多言語面) のみだった
🔹Unicode で BMP 以外がサポートされたのは、2001年3月の Unicode 3.1.0 から
というだけですね。
VB4 は 1995年8月
VB5 は 1997年2月
VB6 は 1998年9月
1991年10月:Unicode 1.0.0
1992年6月:Unicode 1.0.1
1993年6月:Unicode 1.1.0
1993年7月:Unicode 1.1.5
1996年7月:Unicode 2.0.0
1998年5月:Unicode 2.1.0
1999年4月:Unicode 2.1.9
1999年9月:Unicode 3.0.0
2000年8月:Unicode 3.0.1
2001年3月:Unicode 3.1.0
済みません! この部分、大嘘でした。
VB4 が Unicode 3.0 を扱えるというのは間違いです。
🔹VB4 が扱える範囲は BMP(基本多言語面) のみだった
🔹Unicode で BMP 以外がサポートされたのは、2001年3月の Unicode 3.1.0 から
というだけですね。
VB4 は 1995年8月
VB5 は 1997年2月
VB6 は 1998年9月
1991年10月:Unicode 1.0.0
1992年6月:Unicode 1.0.1
1993年6月:Unicode 1.1.0
1993年7月:Unicode 1.1.5
1996年7月:Unicode 2.0.0
1998年5月:Unicode 2.1.0
1999年4月:Unicode 2.1.9
1999年9月:Unicode 3.0.0
2000年8月:Unicode 3.0.1
2001年3月:Unicode 3.1.0
投稿者 魔界の仮面弁士 (社会人)
投稿日時
2021/10/5 14:29:43
るきおさん:
> If cp1 <= 65535 Then
> Debug.WriteLine("鯖はUnicode第1面にあります。")
第1面ではなく、第0面ですよね。
snowmansnowさん:
> Cells(3, 4).VALUE = uni2(55405, 57158)
> Cells(6, 4).VALUE = uni5(9977, 65039, 8205, 9792, 65039)
この部分、中身は ChrW を呼んでいるだけのようですが、
uni2~uni5 と分けるのではなく、ParamArray を使った方がスマートかと思います。
結果はこれで良いのですよね。
> UTF-16のHEX?列で表現される文字は
> ①UTF-16が1個 通常の文字
> ②UTF-16が2個 サロゲートペア
> ③UTF-16が3個 異体字
> ④UTF-16が4個 サロゲートペア異体字
> ⑤UTF-16が4個以上 結合文字
> と、思っております。
> ②~④(か、⑤も)
> について、知りたいです
質問の意味が良く分かりませんが:
たとえば「á」であれば
U+0061 (アルファベットの小文字エー) に
U+0301 (合成用アキュート・アクセント記号)を組み合わせたものであり、
UTF-8 では 3 バイト(61 CC 81)
UTF-16では 4 バイト(0061 0301) で表現されます。
一方で「á」の場合には
U+00E1 (アキュート・アクセント付き小文字エー)であり、
UTF-8 では 2 バイト(C3 A1)
UTF-16では 2 バイト(00E1) で表現されます。
JIS X 0212 では 2 バイト(2B 21) [11区1点] で、
EUC-JPだと 3 バイト(8F AB A1) [11区1点] です。
そして「á」と「á」のいずれも BMP であり、サロゲート領域は必要としません。
あるいは家族絵文字「👩🏻👩🏿👧🏼👧🏾」。これは 1 書記素として描画されますが、
その表現には 11 個のコードポイントが用いられており、
UTF-8 では 41バイト、UTF-16 では 38バイトとなります。
https://j.mp/3a7n8Hy
> 1面のintしか受け付けないのかと勘違いして、2面以降はどうすればいいのか質問した感じでした。
UTF-16 のことですよね。0 面(0000~FFFF)は無加工なので良いとして、
1~16面(10000~10FFFF)で、サロゲートペアの使い方は変わりません。
異体字だろうと結合文字であろうと同じこと。
通常はビットシフトで処理されることが多いですが、
ここでは説明のため、2 進数文字列として処理してみます。
・ベースとなるのは、31ビットの符号化文字集合である UCS-4 (ISO/IEC 10646) という規格です。
"UCS" の由来は、Universal Character Set です。
・UCS-4では、符号位置として 0~7FFFFFFF の 4 バイトで表現されており、
それを上位から「群:0~127」「面:0~255」「区:0~255」「点:0~255」で区切って管理しています。
・Unicode は、それらのうち、0~10FFFF にあたる第0群 第0~16面 のみを扱います。
このため Unicode の符号空間には「群」が無く、「面・区・点」でのみ管理されます。
・UTF-32 は、その 0~10FFFF の文字集合をそのまま符号化するもので、
UCS-4 の部分集合にあたります。
"UTF" の由来は、Unicode (または UCS) Transformation Format だそうです。
・UCS-2 ではその内、0000~FFFF の範囲(第 0 群第 0 面)のみを扱います。
この範囲は特に、BMP(基本多言語面) と呼ばれます。
VB4 (32bit) が扱える Unicode バージョンは 3.0 であり、実質的にはこの範囲に相当します。
※厳密に言えば、VB4 は OS 既定のコードページも扱える仕様なので、たとえば
Shift_JIS では区別されるが、Unicode では同一視される文字なども扱えます。
・BMP は、UCS-2 が扱える唯一の面であり、UCS-4 および Unicode の最初の面です。
BMP の符号位置は、UTF-8 では 1~3 バイト、UTF-16 では 2 バイトで表現されます。
・UTF-16 では BMP(第 0 面) に加えて、サロゲートペアを使うことで、
第 1 面~第 16 面の文字を扱えます。符号空間としては 0~10FFFF の範囲です。
VB.NET が扱う文字列は、内部的にはこの符号化方式で保持されています。
※0000~FFFF で 65,536、10000~10FFFF で 1,048,576、そしてそこから
サロゲート領域の 2,048 文字を引いて、合計 111万2,064文字分の空間)
・サロゲートペアを使うのは UTF-16 のみです。
UTF-8 や UTF-32 は、0~10FFFF の範囲をそのまま符号化できます。
> If cp1 <= 65535 Then
> Debug.WriteLine("鯖はUnicode第1面にあります。")
第1面ではなく、第0面ですよね。
snowmansnowさん:
> Cells(3, 4).VALUE = uni2(55405, 57158)
> Cells(6, 4).VALUE = uni5(9977, 65039, 8205, 9792, 65039)
この部分、中身は ChrW を呼んでいるだけのようですが、
uni2~uni5 と分けるのではなく、ParamArray を使った方がスマートかと思います。
Function Uni(ParamArray charCode() As Variant) As String
Uni = ""
Dim v As Variant
For Each v In charCode
Uni = Uni & ChrW(v)
Next
End Function結果はこれで良いのですよね。
折
𫝆
葛󠄀
𠮟󠄀
⛹️♀️
𩸽󠄁
𩸽󠄊
𫝆
葛󠄀
𠮟󠄀
⛹️♀️
𩸽󠄁
𩸽󠄊
Cells(2, 4).Value = ChrW(&H6298)
Cells(3, 4).Value = ChrW(&HD86D) & ChrW(&HDF46)
Cells(4, 4).Value = ChrW(&H845B) & ChrW(&HDB40) & ChrW(&HDD00)
Cells(5, 4).Value = ChrW(&HD842) & ChrW(&HDF9F) & ChrW(&HDB40) & ChrW(&HDD00)
Cells(6, 4).Value = ChrW(&H26F9) & ChrW(&HFE0F) & ChrW(&H200D) & ChrW(&H2640) & ChrW(&HFE0F)
Cells(7, 4).Value = ChrW(&HD867) & ChrW(&HDE3D) & ChrW(&HDB40) & ChrW(&HDD01)
Cells(8, 4).Value = ChrW(&HD867) & ChrW(&HDE3D) & ChrW(&HDB40) & ChrW(&HDD0A)> UTF-16のHEX?列で表現される文字は
> ①UTF-16が1個 通常の文字
> ②UTF-16が2個 サロゲートペア
> ③UTF-16が3個 異体字
> ④UTF-16が4個 サロゲートペア異体字
> ⑤UTF-16が4個以上 結合文字
> と、思っております。
> ②~④(か、⑤も)
> について、知りたいです
質問の意味が良く分かりませんが:
たとえば「á」であれば
U+0061 (アルファベットの小文字エー) に
U+0301 (合成用アキュート・アクセント記号)を組み合わせたものであり、
UTF-8 では 3 バイト(61 CC 81)
UTF-16では 4 バイト(0061 0301) で表現されます。
一方で「á」の場合には
U+00E1 (アキュート・アクセント付き小文字エー)であり、
UTF-8 では 2 バイト(C3 A1)
UTF-16では 2 バイト(00E1) で表現されます。
JIS X 0212 では 2 バイト(2B 21) [11区1点] で、
EUC-JPだと 3 バイト(8F AB A1) [11区1点] です。
そして「á」と「á」のいずれも BMP であり、サロゲート領域は必要としません。
あるいは家族絵文字「👩🏻👩🏿👧🏼👧🏾」。これは 1 書記素として描画されますが、
その表現には 11 個のコードポイントが用いられており、
UTF-8 では 41バイト、UTF-16 では 38バイトとなります。
https://j.mp/3a7n8Hy
> 1面のintしか受け付けないのかと勘違いして、2面以降はどうすればいいのか質問した感じでした。
UTF-16 のことですよね。0 面(0000~FFFF)は無加工なので良いとして、
1~16面(10000~10FFFF)で、サロゲートペアの使い方は変わりません。
異体字だろうと結合文字であろうと同じこと。
通常はビットシフトで処理されることが多いですが、
ここでは説明のため、2 進数文字列として処理してみます。
Public Function ToUTF16(codePage As Integer) As UShort()
If codePage < 0 OrElse &H10FFFF < codePage Then
Throw New ArgumentOutOfRangeException(NameOf(codePage))
End If
If codePage <= &HFFFF Then
'BMP の場合は無加工
Return New UShort() {CUShort(codePage)}
Else
'①元の値から 0x10000 を引くことで、U+010000~U+10FFFF を 00000~FFFFF にする
Dim u = CUShort(codePage - &H10000UI)
'②それを 20ビットの2進数として表現
Dim b = Convert.ToString(u, 2).PadLeft(20, "0"c)
'③上位サロゲートは、上位10ビットの前に"110110"を添えた値
Dim us = CUShort(Convert.ToInt32("110110" & b.Substring(0, 10), 2))
'④下位サロゲートは、下位10ビットの前に"110111"を添えた値
Dim ls = CUShort(Convert.ToInt32("110111" & b.Substring(10, 10), 2))
Return {us, ls}
End If
End Function・ベースとなるのは、31ビットの符号化文字集合である UCS-4 (ISO/IEC 10646) という規格です。
"UCS" の由来は、Universal Character Set です。
・UCS-4では、符号位置として 0~7FFFFFFF の 4 バイトで表現されており、
それを上位から「群:0~127」「面:0~255」「区:0~255」「点:0~255」で区切って管理しています。
・Unicode は、それらのうち、0~10FFFF にあたる第0群 第0~16面 のみを扱います。
このため Unicode の符号空間には「群」が無く、「面・区・点」でのみ管理されます。
・UTF-32 は、その 0~10FFFF の文字集合をそのまま符号化するもので、
UCS-4 の部分集合にあたります。
"UTF" の由来は、Unicode (または UCS) Transformation Format だそうです。
・UCS-2 ではその内、0000~FFFF の範囲(第 0 群第 0 面)のみを扱います。
この範囲は特に、BMP(基本多言語面) と呼ばれます。
VB4 (32bit) が扱える Unicode バージョンは 3.0 であり、実質的にはこの範囲に相当します。
※厳密に言えば、VB4 は OS 既定のコードページも扱える仕様なので、たとえば
Shift_JIS では区別されるが、Unicode では同一視される文字なども扱えます。
・BMP は、UCS-2 が扱える唯一の面であり、UCS-4 および Unicode の最初の面です。
BMP の符号位置は、UTF-8 では 1~3 バイト、UTF-16 では 2 バイトで表現されます。
・UTF-16 では BMP(第 0 面) に加えて、サロゲートペアを使うことで、
第 1 面~第 16 面の文字を扱えます。符号空間としては 0~10FFFF の範囲です。
VB.NET が扱う文字列は、内部的にはこの符号化方式で保持されています。
※0000~FFFF で 65,536、10000~10FFFF で 1,048,576、そしてそこから
サロゲート領域の 2,048 文字を引いて、合計 111万2,064文字分の空間)
・サロゲートペアを使うのは UTF-16 のみです。
UTF-8 や UTF-32 は、0~10FFFF の範囲をそのまま符号化できます。
投稿者 (削除されました) ()
投稿日時
2021/10/5 14:20:05
(削除されました)
投稿者 snowmansnow (社会人)
投稿日時
2021/10/3 21:34:58
こんばんは、るきお様、忙しい中、お返事ありがとうございます
コンソールアプリで確認できました。
<UserWPF>true</UserWPF>は、初めてなので勉強になりました。
>>ユニコードで表現される?文字のグリフが、あるフォントに存在するか知りたいです。
𩸽は、29E3D,E0100~29E3D,E0104
①171512,917760②171512,917761③171512,917762④171512,917763
が、あるようですが
IPAmj明朝には、どれがあるか知りたいです。
Moji_Johoには、𩸽が3つあるので、55555、55556,55557どれがどれか分かれば良いかなぁ?と思っていましたが
Moji_Johoには、
29DF8,E0100~29E3D,E0101の文字は、2つあるようですが、
IPAmj明朝のグリフには、55519の1つしかなく、どうなっているのか分かりませんでした。
55555、55557を検索、取得できる方法と、IPAmj明朝には、どれがあるか知りたい は、
同じではないかもしれないので、もし同じでしたら教えて頂きたいです。
急ぎではないので、空き時間ができたら、教えてください。
投稿者 るきお (社会人)
投稿日時
2021/10/3 18:58:01
おっしゃっていることが理解できてきました。
まだ完全ではありません。
文字がフォントに含まれるかどうかは、GlyphTypeface.CharacterToGlyphMap.TryGetValue で判断できます。(判断するだけならContainsKeyの方が簡単です。)
このコンソールアプリケーションを実行するにはプロジェクトファイルの<PropertyGroup>内に<UserWPF>true</UserWPF>を追加する必要があります。面倒ならConsoleの部分をMessageBoxなどに変更すればWPFプロジェクトでも実行できます。
これを ipamjm.ttf で実施すると 55556 を取得し、verdana.ttf でやると文字は含まれていませんと表示されます。
このプログラムでは、まだsnowmansnowさんの知りたいことがわからないのだと思いますが、何か足りないのでしょうか?
>ユニコードで表現される?文字のグリフが、あるフォントに存在するか知りたいです。
これは達成できていると思うのですが…。
>IPAmj明朝で𩸽は、コードポイント171581ですが、取得できるグリフ番号は、55556ですが、
>グリフは、55555、55556、55557の3つです。
>55555、55557を検索、取得できる方法がわかりません。
と以前、書かれているので、何かこのあたりのことはすでに実験済みのように感じました。
いろいろ書きたいのですが、あまり時間が割けずひとまずこのあたりで送信します。
まだ完全ではありません。
文字がフォントに含まれるかどうかは、GlyphTypeface.CharacterToGlyphMap.TryGetValue で判断できます。(判断するだけならContainsKeyの方が簡単です。)
var gtf = new GlyphTypeface(new Uri(@"C:\temp\ipamjm.ttf"));
//var gtf = new GlyphTypeface(new Uri(@"C:\temp\verdana.ttf"));
var b = System.Text.Encoding.UTF32.GetBytes("𩸽");
var codePoint = b[0] + b[1] * 256 + b[2] * 256 * 256 + b[3] * 256 * 256 * 256;
ushort index;
if (gtf.CharacterToGlyphMap.TryGetValue(codePoint, out index))
{
Console.WriteLine($"このフォントでは インデックス {index} にその文字があります。");
}
else
{
Console.WriteLine("このフォントにはその文字は含まれていません。");
}このコンソールアプリケーションを実行するにはプロジェクトファイルの<PropertyGroup>内に<UserWPF>true</UserWPF>を追加する必要があります。面倒ならConsoleの部分をMessageBoxなどに変更すればWPFプロジェクトでも実行できます。
これを ipamjm.ttf で実施すると 55556 を取得し、verdana.ttf でやると文字は含まれていませんと表示されます。
このプログラムでは、まだsnowmansnowさんの知りたいことがわからないのだと思いますが、何か足りないのでしょうか?
>ユニコードで表現される?文字のグリフが、あるフォントに存在するか知りたいです。
これは達成できていると思うのですが…。
>IPAmj明朝で𩸽は、コードポイント171581ですが、取得できるグリフ番号は、55556ですが、
>グリフは、55555、55556、55557の3つです。
>55555、55557を検索、取得できる方法がわかりません。
と以前、書かれているので、何かこのあたりのことはすでに実験済みのように感じました。
いろいろ書きたいのですが、あまり時間が割けずひとまずこのあたりで送信します。
投稿者 snowmansnow (社会人)
投稿日時
2021/10/3 18:18:56
すいません
インストールが必要なフォントは、
https://moji.or.jp/mojikiban/font/を見て、窓の杜からdlできる
IPAmj明朝フォントです
もしかしたら、フォントのフォルダが、それぞれの端末で違うかもしれません。
違うとエラーで、何も表示されません
環境によって
C:\Users\Y2\AppData\Local\Microsoft\Windows\Fonts\ipamjm.ttf
のフォルダを変えて下さい。
C:\Users\Y2\Desktop\ipatest.txtも御自身のフォルダに変更下さい
特に意味のあるファイルではありませんが、将来、フォンなどトも入れたいと思っています
投稿者 snowmansnow (社会人)
投稿日時
2021/10/3 18:03:57
すいません
>⑤UTF-16が4個 結合文字
は、
⑤UTF-16が4個以上 結合文字
の間違いです
>添付のソースコードはipamjm.ttfに含まれるグリフの数を数えるもののようですね。
しばらくするとメッセージボックスで、グリフ数を表示します。
okボタンを押すと、5分くらいで、リストボックスを表示します。
フォントがインストールされていないと、エラーで、何も表示されません
投稿者 snowmansnow (社会人)
投稿日時
2021/10/3 17:55:49
こんばんは、るきお様、お返事ありがとうございます。
>まだやりたいことがわからないのでもっと教えてください。
ユニコードで表現される?文字のグリフが、あるフォントに存在するか知りたいです。
(ユニコードで表現されない文字がフォントにあるかわかりません)
>「サロゲートペア以上」の意味が分からないです。
UTF-16のHEX?列で表現される文字は
①UTF-16が1個 通常の文字
②UTF-16が2個 サロゲートペア
③UTF-16が3個 異体字
④UTF-16が4個 サロゲートペア異体字
⑤UTF-16が4個 結合文字
と、思っております。
②~④(か、⑤も)
について、知りたいです
>サロゲートペアで表現できる文字一覧にその文字が含まれるのか確認したいのか、
はい、でも②は自分でわかるかもしれません
④だけかもしれません
>異体字セレクタで表現できる文字一覧にその文字が含まれているか確認したいのか、
はい、③と④が知りたいです
>あるフォントにその文字を表現するグリフが含まれていることを確認したいのか。
はい、そうだと思います。
>添付のソースコードはipamjm.ttfに含まれるグリフの数を数えるもののようですね。
いいえ、
全グリフをグリフのid順に表示して、
CharacterToGlyphMapで取得されるグリフのidで表示される文字が、
異体字なら、1個なのか、2個以上なのかを確認したかった、ものです。
(https://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=%F0%A9%B8%BD
が、どうして1個で、フォントもそうなのか?、異体字はどういう扱いなのか調べるためです)
何回も、御教授、添削ありがとうございます。
今回は、いかがでしょうか?
投稿者 るきお (社会人)
投稿日時
2021/10/3 15:44:21
こんにちは。
まだやりたいことがわからないのでもっと教えてください。
できましたらシンプルに書いていただければと思います。
例:
○○したいです。
△△まではできました。その方法は□□です。
>サロゲートペア以上のUTF-16が2つ以上の文字(異体字)の(フォントなどの存在)確認方法
「サロゲートペア以上」の意味が分からないです。
数字なら100以上とか、32以上とか意味が分かるのですが、サロゲートペアは何かの順番を表しているわけではないので「以上」「以下」という表現の意味が分かりません。
たとえば、「ワイシャツ以上のカシミアが2以上の服(袖あり)」と言われているような感覚です。
それから、UTF-16は数えられるものではないので、「UTF-16が2つ以上」いう表現が理解しにくいです。
ここは何か根本的に誤解されているのではないかと感じます。
「Unicodeの2つ以上のコードポイントで1文字を表す文字」と言われたいのでしょうか?
そのような文字にはサロゲートペアの他、異体字セレクターなどの結合文字があります。
snowmansanowさんが、ここで対象に考えたいのは異体字セレクターが使用される場面であって、そのほかのことは対象にしないというのが「文字(異体字)」という表現の含意でしょうか。
この文の全体の意味もわからないです。
文字の確認方法が知りたいという趣旨は理解できました。
Unicodeでその文字が定義されているか確認したいのか、
サロゲートペアで表現できる文字一覧にその文字が含まれるのか確認したいのか、
異体字セレクタで表現できる文字一覧にその文字が含まれているか確認したいのか、
あるフォントにその文字を表現するグリフが含まれていることを確認したいのか。
具体例を挙げていただくのもよいかもしれません。
たとえば、『ipamjm.ttf に含まれる「花」の異体字を取得する方法が知りたい』のような感じです。
(ちなみにこの質問の答えを私は知りません)
このような感じで、1文1文解釈が難しく、snowmansnow さんがやりたいことがよくわからないわけです。
添付のソースコードはipamjm.ttfに含まれるグリフの数を数えるもののようですね。
他にもわからない点があるのですが、いろいろ聞くと話が発散してしまうので、まず気になった点からお伺いしました。
まだやりたいことがわからないのでもっと教えてください。
できましたらシンプルに書いていただければと思います。
例:
○○したいです。
△△まではできました。その方法は□□です。
>サロゲートペア以上のUTF-16が2つ以上の文字(異体字)の(フォントなどの存在)確認方法
「サロゲートペア以上」の意味が分からないです。
数字なら100以上とか、32以上とか意味が分かるのですが、サロゲートペアは何かの順番を表しているわけではないので「以上」「以下」という表現の意味が分かりません。
たとえば、「ワイシャツ以上のカシミアが2以上の服(袖あり)」と言われているような感覚です。
それから、UTF-16は数えられるものではないので、「UTF-16が2つ以上」いう表現が理解しにくいです。
ここは何か根本的に誤解されているのではないかと感じます。
「Unicodeの2つ以上のコードポイントで1文字を表す文字」と言われたいのでしょうか?
そのような文字にはサロゲートペアの他、異体字セレクターなどの結合文字があります。
snowmansanowさんが、ここで対象に考えたいのは異体字セレクターが使用される場面であって、そのほかのことは対象にしないというのが「文字(異体字)」という表現の含意でしょうか。
この文の全体の意味もわからないです。
文字の確認方法が知りたいという趣旨は理解できました。
Unicodeでその文字が定義されているか確認したいのか、
サロゲートペアで表現できる文字一覧にその文字が含まれるのか確認したいのか、
異体字セレクタで表現できる文字一覧にその文字が含まれているか確認したいのか、
あるフォントにその文字を表現するグリフが含まれていることを確認したいのか。
具体例を挙げていただくのもよいかもしれません。
たとえば、『ipamjm.ttf に含まれる「花」の異体字を取得する方法が知りたい』のような感じです。
(ちなみにこの質問の答えを私は知りません)
このような感じで、1文1文解釈が難しく、snowmansnow さんがやりたいことがよくわからないわけです。
添付のソースコードはipamjm.ttfに含まれるグリフの数を数えるもののようですね。
他にもわからない点があるのですが、いろいろ聞くと話が発散してしまうので、まず気になった点からお伺いしました。
投稿者 snowmansnow (社会人)
投稿日時
2021/10/3 14:23:03
ごめんなさい。3つ目です
参照のアセンブリで
PresentationCoreと
PresentationFrameworkを参照してください
投稿者 snowmansnow (社会人)
投稿日時
2021/10/3 13:52:17
ごめんなさい。2つ目です
MainWindow.xaml
MainWindow.xaml
<Window x:Class="WpfApp1_CMAP_CS.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:local="clr-namespace:WpfApp1_CMAP_CS"
mc:Ignorable="d"
Title="MainWindow" Height="300" Width="300">
<ScrollViewer HorizontalScrollBarVisibility="Auto" VerticalScrollBarVisibility="Auto">
<Grid>
<StackPanel>
<ListBox ItemsSource="{Binding GlyphItems}">
<ListBox.ItemTemplate>
<DataTemplate>
<Grid>
<Grid.ColumnDefinitions>
<ColumnDefinition Width="50"/>
<ColumnDefinition/>
</Grid.ColumnDefinitions>
<Glyphs FontUri="{Binding FontUri}" Indices="{Binding Indices}"
FontRenderingEmSize="36" OriginX="10" OriginY="36"
Fill="Black"/>
<TextBlock Grid.Column="1" VerticalAlignment="Center"
Text="{Binding Indices, StringFormat=Index {0}}"/>
</Grid>
</DataTemplate>
</ListBox.ItemTemplate>
</ListBox>
</StackPanel>
</Grid>
</ScrollViewer>
</Window>
投稿者 snowmansnow (社会人)
投稿日時
2021/10/3 13:51:29
こんにちは、るきお様、魔界の仮面弁士様
今週は、体調不良でお返事が遅くなり申し訳ございません
魔界の仮面弁士様のwebは、勉強の一部で、質問のintは含まれていませんでした・・・
何人ものwebをググって、体調不良で。こんがらがってしまいました。
1面のintしか受け付けないのかと勘違いして、2面以降はどうすればいいのか質問した感じでした。
intの部分は、コードポイントの事でしたので、2面以降も対応してるのが自分でわかりました。
何人ものwebをググって、質問さえ、何がなんだかこんがらがっていたと思います。
皆様、混乱させて申し訳ございませんでした。
異体字は、コードポイントが2つ?(1つとセレクタ?)になるので、
utf-32の2つ時に、どうすれば良いのか悩んでたのだと思います
utf-32の2つの時は、1つめだけのようで、2つ目の扱いが不明です。
教えていただいた
https://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=%F0%A9%B8%BD
では、1つ目のみで𩸽を表示できてるようでして、
netでも、そんな感じなのを確認でき始めていて、質問が変化してきております。
今のところ、エクセルで実現できる気がしていないので、エクセルにこだわっていは、いません。
サロゲートペア以上のUTF-16が2つ以上の文字(異体字)の(フォントなどの存在)確認方法
になると、思います。
utf-32の2つの時に、①2つのコードポイント、②1つのコードポイントと何か?を悩んでいたので
文字化けでなく、コードポイント?という表記をさせていただいてました。
フォント”など”の部分は、IVD_Sequences.txtになるのかもしれませんが、
フォント""では、どうなるのかを知りたかったと、思います。
フォントから指定した文字を取り出すような処理を組む必要があるのではないか
は、まさしくそれで、今、自分で、取り組んでます。
CSのWPFのNetFrameworkで、文字をグリフインデックスで表示して、
コードポイントでグリフインデックスで探し、異体字のグリフがどうなっているか、調査中で、
コードポイントでは、複数の異体字のグリフを探せない。というトラブルになっています。
IPAmj明朝で𩸽は、コードポイント171581ですが、取得できるグリフ番号は、55556ですが、
グリフは、55555、55556、55557の3つです。
55555、55557を検索、取得できる方法がわかりません。
さらに、それぞれの異体字セレクタを取得できる方法がわかりません。
取得できたら、逆さに検索もできる気もしています。
現状のCSのWPFのNetFrameworkは、下記です
55556付近を見ると、𩸽が3つあるのが分かると思います。
いつも短くしたつもりですが、また2つになりました、ごめんなさい。
MainWindow.xaml.cs
今週は、体調不良でお返事が遅くなり申し訳ございません
魔界の仮面弁士様のwebは、勉強の一部で、質問のintは含まれていませんでした・・・
何人ものwebをググって、体調不良で。こんがらがってしまいました。
1面のintしか受け付けないのかと勘違いして、2面以降はどうすればいいのか質問した感じでした。
intの部分は、コードポイントの事でしたので、2面以降も対応してるのが自分でわかりました。
何人ものwebをググって、質問さえ、何がなんだかこんがらがっていたと思います。
皆様、混乱させて申し訳ございませんでした。
異体字は、コードポイントが2つ?(1つとセレクタ?)になるので、
utf-32の2つ時に、どうすれば良いのか悩んでたのだと思います
utf-32の2つの時は、1つめだけのようで、2つ目の扱いが不明です。
教えていただいた
https://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=%F0%A9%B8%BD
では、1つ目のみで𩸽を表示できてるようでして、
netでも、そんな感じなのを確認でき始めていて、質問が変化してきております。
今のところ、エクセルで実現できる気がしていないので、エクセルにこだわっていは、いません。
サロゲートペア以上のUTF-16が2つ以上の文字(異体字)の(フォントなどの存在)確認方法
になると、思います。
utf-32の2つの時に、①2つのコードポイント、②1つのコードポイントと何か?を悩んでいたので
文字化けでなく、コードポイント?という表記をさせていただいてました。
フォント”など”の部分は、IVD_Sequences.txtになるのかもしれませんが、
フォント""では、どうなるのかを知りたかったと、思います。
フォントから指定した文字を取り出すような処理を組む必要があるのではないか
は、まさしくそれで、今、自分で、取り組んでます。
CSのWPFのNetFrameworkで、文字をグリフインデックスで表示して、
コードポイントでグリフインデックスで探し、異体字のグリフがどうなっているか、調査中で、
コードポイントでは、複数の異体字のグリフを探せない。というトラブルになっています。
IPAmj明朝で𩸽は、コードポイント171581ですが、取得できるグリフ番号は、55556ですが、
グリフは、55555、55556、55557の3つです。
55555、55557を検索、取得できる方法がわかりません。
さらに、それぞれの異体字セレクタを取得できる方法がわかりません。
取得できたら、逆さに検索もできる気もしています。
現状のCSのWPFのNetFrameworkは、下記です
55556付近を見ると、𩸽が3つあるのが分かると思います。
いつも短くしたつもりですが、また2つになりました、ごめんなさい。
MainWindow.xaml.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows;
using System.Windows.Controls;
using System.Windows.Data;
using System.Windows.Documents;
using System.Windows.Input;
using System.Windows.Media;
using System.Windows.Media.Imaging;
using System.Windows.Navigation;
using System.Windows.Shapes;
using System.Collections.ObjectModel;
namespace WpfApp1_CMAP_CS
{
///'https://anderson02.com/cs/wpf/wpf-21/
/// <summary>
/// MainWindow.xaml の相互作用ロジック
/// </summary>
public partial class MainWindow : Window
{
int ii = 0;
public MainWindow()
{
InitializeComponent();
GlyphItems = new List<object>();
System.IO.StreamWriter sw = new System.IO.StreamWriter( @"C:\Users\Y2\Desktop\ipatest.txt", false);
//TextBox1.Textの内容を1行ずつ書き込む
var font = @"C:\Users\Y2\AppData\Local\Microsoft\Windows\Fonts\ipamjm.ttf";
//var font = @"C:\Windows\Fonts\meiryo.ttc";
for (int i = 0; i < new GlyphTypeface(new Uri(font)).GlyphCount; i++)
// for (int i = 0; i < 100; i++)
{
GlyphItems.Add(new { FontUri = font, Indices = i.ToString() });
ii = i;
sw.WriteLine(new { FontUri = font, Indices = i.ToString() });
}
MessageBox.Show(Convert.ToString(ii));
//https://www.sejuku.net/blog/57946
DataContext = this;
//閉じる
sw.Close();
}
public List<object> GlyphItems { get; set; }
}
}
投稿者 るきお (社会人)
投稿日時
2021/10/2 09:54:55
snowmansnowさん、もう少しポイントを絞っていただくと、話がしやすくなると思います。
ご質問が下記URLの話から始まるので、そもそもはじめてにこのURLを見て、中身を理解する必要があります。
http://bbs.wankuma.com/index.cgi?mode=al2&namber=79406&KLOG=135
これだけでもう時間がかかかります。
何かに依存するのではなく、この投稿だけで話がわかるのようになっていると、取り組みやすいです。
(よくこれを「コンテキストに依存しない」と呼びます。)
悪い例 (コンテキストに依存している)
・以前(2020/4/5)の投稿の件なのですが…
・http://xxxxx/ の件ですが…
・この前相談した、在庫管理システムについてですが…
・前回の続きです。
正直言うと、このようなコンテキスト依存の書き込みは、中身を見る気力がとても低くなります。
以前のことに触れたければ、背景で参考程度に書くのが良いと思います。あくまで参考なので、そのことは知らなくても良いというレベルです。
そして、その後に、Excel VBAで作られた動かない長いプログラムを投稿されていますね。
これは長いだけではなく、具体的に何を聞きたいのかがわからないのでポイントを絞りにくいです。
困っていることを具体的に説明できる最小限のプログラムを投稿するのがセオリーです。
既存のプログラムを切り貼りしてうまく説明できない場合は、投稿用に小さいプログラムを作り直すということをやります。
そのうえで、○○行目でエラーxxxxが発生します。とか、○○行目でこういう処理をしたいのだけれどもそのやり方がわからない という説明をします。
さて、今回の件ですが、
これがやってみたいことでしょうか?
>サロゲートペア以上のUTF-16が2つ以上の文字の確認方法
つまり、ある文字が、Unicodeの第1面で定義されているのか、2面以降で定義されているのかを確認したいということであっていますか?
(サロゲートペアでの表現が必要になるのは、第2面以降なので)
ちなみに、Excelで実現したいのでしょうか?
ひとまず、VB(.NETの方)では次のようにして確認できます。
このロジックは、コードポイントを見て、Unicode第1面かそれ以降かを判断しています。
現在、Unicodeのコードポイントを取得する一般的な方法は System.Text.Encoding.UTF32.GetBytes ではないかと思います。
UTF32はUnicodeのコードポイントをそのまま使用する符号化方式なので、UTF32で符号化したものの値を取得するということは、コードポイントを取得するのと同じ意味になります。
(ただ、バイトオーダー(並び順)は人間の感覚と異なるので注意が必要です。)
>Unicode文字の、コードポイント?とUTF-16と異体字セレクタを確認する早見式でした。
コードポイントの取得方法は上述の通りです。
UTF-16で符号化された結果を取得したい場合は、上述の式で UTF32 の代わりに UTF16 を使用します。
異体字セレクタは、コードポイントを調べればわかりますね。
>コードポイント?が2つ?の(あ)異体字と(い)サロゲートペア異体字のフォント内のグリフ?の確認方法を
ここの ? が意味が分からないです。掲示板で文字化けしてしまったでしょうか?
Unihanデータベースを使うとグリフを確認できます。
https://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=%F0%A9%B8%BD
異体字セレクタで具体的にどのような外見が媒体に表示されるかの取得方法はちょっと私にはわかりません。フォント側の対応も必要なので、フォントから指定した文字を取り出すような処理を組む必要があるのではないかと思います。
ご質問が下記URLの話から始まるので、そもそもはじめてにこのURLを見て、中身を理解する必要があります。
http://bbs.wankuma.com/index.cgi?mode=al2&namber=79406&KLOG=135
これだけでもう時間がかかかります。
何かに依存するのではなく、この投稿だけで話がわかるのようになっていると、取り組みやすいです。
(よくこれを「コンテキストに依存しない」と呼びます。)
悪い例 (コンテキストに依存している)
・以前(2020/4/5)の投稿の件なのですが…
・http://xxxxx/ の件ですが…
・この前相談した、在庫管理システムについてですが…
・前回の続きです。
正直言うと、このようなコンテキスト依存の書き込みは、中身を見る気力がとても低くなります。
以前のことに触れたければ、背景で参考程度に書くのが良いと思います。あくまで参考なので、そのことは知らなくても良いというレベルです。
そして、その後に、Excel VBAで作られた動かない長いプログラムを投稿されていますね。
これは長いだけではなく、具体的に何を聞きたいのかがわからないのでポイントを絞りにくいです。
困っていることを具体的に説明できる最小限のプログラムを投稿するのがセオリーです。
既存のプログラムを切り貼りしてうまく説明できない場合は、投稿用に小さいプログラムを作り直すということをやります。
そのうえで、○○行目でエラーxxxxが発生します。とか、○○行目でこういう処理をしたいのだけれどもそのやり方がわからない という説明をします。
さて、今回の件ですが、
これがやってみたいことでしょうか?
>サロゲートペア以上のUTF-16が2つ以上の文字の確認方法
つまり、ある文字が、Unicodeの第1面で定義されているのか、2面以降で定義されているのかを確認したいということであっていますか?
(サロゲートペアでの表現が必要になるのは、第2面以降なので)
ちなみに、Excelで実現したいのでしょうか?
ひとまず、VB(.NETの方)では次のようにして確認できます。
'▼鯖の場合
'https://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=%E9%AF%96
'鯖のコードポイントを を4つのバイトの配列で取得します。
Dim b1 As Byte() = System.Text.Encoding.UTF32.GetBytes("鯖")
'鯖のコードポイントを 1つの数値で取得します。
Dim cp1 As Long = b1(0) + b1(1) * 256 + b1(2) * 256 * 256 + b1(3) * 256 * 256 * 256
'16進数での表現も取得しておきます。
Dim cp1_16 As String = BitConverter.ToString(b1.Reverse.ToArray).Replace("-", "")
Debug.WriteLine("鯖のコードポイントは " & cp1 & " = " & cp1_16)
If cp1 <= 65535 Then
Debug.WriteLine("鯖はUnicode第1面にあります。")
Else
Debug.WriteLine("鯖はUnicode第2面以降にあります。")
End If
'▼𩸽の場合
'https://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=%F0%A9%B8%BD
'𩸽のコードポイントを を4つのバイトの配列で取得します。
Dim b2 As Byte() = System.Text.Encoding.UTF32.GetBytes("𩸽")
'𩸽のコードポイントを 1つの数値で取得します。
Dim cp2 As Long = b2(0) + b2(1) * 256 + b2(2) * 256 * 256 + b2(3) * 256 * 256 * 256
'16進数での表現も取得しておきます。
Dim cp2_16 As String = BitConverter.ToString(b2.Reverse.ToArray).Replace("-", "")
Debug.WriteLine("鯖のコードポイントは " & cp2 & " = " & cp2_16)
If cp2 <= 65535 Then
Debug.WriteLine("𩸽はUnicode第1面にあります。")
Else
Debug.WriteLine("𩸽はUnicode第2面以降にあります。")
End Ifこのロジックは、コードポイントを見て、Unicode第1面かそれ以降かを判断しています。
現在、Unicodeのコードポイントを取得する一般的な方法は System.Text.Encoding.UTF32.GetBytes ではないかと思います。
UTF32はUnicodeのコードポイントをそのまま使用する符号化方式なので、UTF32で符号化したものの値を取得するということは、コードポイントを取得するのと同じ意味になります。
(ただ、バイトオーダー(並び順)は人間の感覚と異なるので注意が必要です。)
>Unicode文字の、コードポイント?とUTF-16と異体字セレクタを確認する早見式でした。
コードポイントの取得方法は上述の通りです。
UTF-16で符号化された結果を取得したい場合は、上述の式で UTF32 の代わりに UTF16 を使用します。
異体字セレクタは、コードポイントを調べればわかりますね。
>コードポイント?が2つ?の(あ)異体字と(い)サロゲートペア異体字のフォント内のグリフ?の確認方法を
ここの ? が意味が分からないです。掲示板で文字化けしてしまったでしょうか?
Unihanデータベースを使うとグリフを確認できます。
https://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=%F0%A9%B8%BD
異体字セレクタで具体的にどのような外見が媒体に表示されるかの取得方法はちょっと私にはわかりません。フォント側の対応も必要なので、フォントから指定した文字を取り出すような処理を組む必要があるのではないかと思います。
投稿者 snowmansnow (社会人)
投稿日時
2021/10/1 08:39:57
おはようございます魔界の弁士様
昨日は体調不良で寝てしまいました。
①冒頭の「A」って何ですか?
ここで「コンパイル エラー:変数が定義されていません。」で止まります。
VBAで、マクロの表示をすると、何でも表示されてしまうので、
subに何か、変数を渡す形にすると、表示されないための対策の癖でした。
何も使ってません。
Dim A as integer などしてから呼び出すと、問題ないと思います。
定義し忘れました。ごめんなさい。
②ここの「y」も未定義。
Option Explicit を付ける癖を付けましょう。
はい、今回は大分気を使ったつもりでしたが、人力で漏れました。ごめんなさい
③これも変数宣言が無くて謎。
というか他で使われていないのでは?
引用した元で使っていて、勉強になったので消し忘れました。
④このほか、各種 Function の戻り値の型が未設定なのも辛いところ。
とりあえず「DefVar A-Z」を宣言しておきましたが…。
SPP()はString
I異体字4()、uni2()、uni3()、uni4()、uni5()もStringです。
⑤他にも「ASCW2」が未定義など
モジュールが違ってコピーしもれました
Function ASCW2(VALUE As Long) As Long
If VALUE < 0 Then
ASCW2 = 65536 + VALUE
Else
ASCW2 = VALUE
End If
End Function
⑥何をするためのコードか
Unicode文字の、コードポイント?とUTF-16と異体字セレクタを確認する早見式でした。
コードポイント?が2つ?の(あ)異体字と(い)サロゲートペア異体字のフォント内のグリフ?の確認方法を
教えて頂きたかったでした。
魔界の仮面弁士様、皆さま、貴重なお時間無駄にさせて大変申し訳ございません。
IVD_Sequences.txtは、https://github.com/adobe-type-tools/pancjkv-ivd-collectionなどに
あります。でも2007-12-14なので古いかもしれません。
まこ様の後、勉強してて、早見式は出せるようになったですが、フォント内のグリフ?の確認を
してみたくなり、自分ではどうしてもわからなかったので、御質問いたしました。
あきれないで、あともう少しコストを割いて頂けると、大変ありがたいです。
投稿者 魔界の仮面弁士 (社会人)
投稿日時
2021/9/30 10:55:13
名前からして、Sub Main() が最初に呼び出すべきエントリポイントだとは思ったのですが:
> Sub MAIN()
> Call IVDINI(A)
冒頭の「A」って何ですか?
ここで「コンパイル エラー:変数が定義されていません。」で止まります。
> For y = 2 To 8
ここの「y」も未定義。
Option Explicit を付ける癖を付けましょう。
> myLine = CLng(Text2)
これも変数宣言が無くて謎。
というか他で使われていないのでは?
このほか、各種 Function の戻り値の型が未設定なのも辛いところ。
とりあえず「DefVar A-Z」を宣言しておきましたが…。
他にも「ASCW2」が未定義など、動作確認できるまでにかかるコストが高すぎて、
何をするためのコードか解析するのを諦めてしまいました。
> Sub MAIN()
> Call IVDINI(A)
冒頭の「A」って何ですか?
ここで「コンパイル エラー:変数が定義されていません。」で止まります。
> For y = 2 To 8
ここの「y」も未定義。
Option Explicit を付ける癖を付けましょう。
> myLine = CLng(Text2)
これも変数宣言が無くて謎。
というか他で使われていないのでは?
このほか、各種 Function の戻り値の型が未設定なのも辛いところ。
とりあえず「DefVar A-Z」を宣言しておきましたが…。
他にも「ASCW2」が未定義など、動作確認できるまでにかかるコストが高すぎて、
何をするためのコードか解析するのを諦めてしまいました。
投稿者 snowmansnow (社会人)
投稿日時
2021/9/29 21:54:11
こんばんは、長くて入らなかった2回目です
Sub IVDINI(A)
'ファイルの指定行を読込
Dim I As Long
Dim Fso As New FileSystemObject
'Microsoft Scripting Runtime に参照設定
Dim FsoTS As TextStream
Dim SCA As String
Dim SEL As String
Dim SCAM As Long
Dim SELM As Long
Dim TEXT1 As String
Dim N As Long
Dim M As Long
Dim I2 As Long
Dim e As Long
TEXT1 = ""
myLine = CLng(Text2)
Set FsoTS = Fso.OpenTextFile("C:\Users\Y2\Desktop\IVD_Sequences.txt")
N = 0
M = 0
e = 0
While e <> 1
If FsoTS.AtEndOfStream = False Then
M = M + 1
TEXT1 = FsoTS.ReadLine
If Left(TEXT1, 1) <> "#" Then
N = N + 1
ReDim Preserve SCA1(N)
ReDim Preserve SCA2(N)
ReDim Preserve SEL1(N)
ReDim Preserve SEL2(N)
SCA = SPP(TEXT1, 0, " ")
SEL = SPP(SPP(TEXT1, 0, ";"), 1, " ")
SCAM = Application.Hex2Dec(SCA)
SELM = Application.Hex2Dec(SEL) - 917760
SCA1(N) = SCA
SCA2(N) = SCAM
SEL1(N) = SEL
SEL2(N) = SELM
Else
End If
Else
e = 1
End If
Wend
FsoTS.Close
Set FsoTS = Nothing
End Sub
Function IVD(SCATEST As Long, SELTEST As Long) As String
Dim N As Long
Dim M As Long
Dim I2 As Long
Dim e As Long
N = UBound(SCA1())
For I = 1 To N
If SCA2(I) = SCATEST Then
For I2 = I To N
If (SCA2(I2) = SCATEST) * (SEL2(I2) = SELTEST) Then
IVD = "有"
I2 = N
I = N
Exit For
Else
IVD = "偽"
End If
Next
Else
IVD = "偽"
End If
Next
End Function
Function SPP(w As String, N As Long, SEP As String)
'http://www.eurus.dti.ne.jp/~yoneyama/Excel/vba/function/vba_string2.html
Dim S As Variant
Dim WW As String
S = Split(w, SEP)
WW = S(N)
SPP = WW
End Function
Function I異体字4(A, b, c, d)
I異体字4 = ChrW(A) & ChrW(b) & ChrW(c) & ChrW(&HDD00 + d) '異体字連結
End Function
Function uni2(A, b)
uni2 = ChrW(A) & ChrW(b)
End Function
Function uni3(A, b, c)
uni3 = ChrW(A) & ChrW(b) & ChrW(c)
End Function
Function uni4(A, b, c, d)
uni4 = ChrW(A) & ChrW(b) & ChrW(c) & ChrW(d)
End Function
Function uni5(A, b, c, d, e)
uni5 = ChrW(A) & ChrW(b) &ChrW(c) & ChrW(d) & ChrW(e)
End Function
投稿者 snowmansnow (社会人)
投稿日時
2021/9/29 21:52:18
こんばんは、るきお様、魔界の仮面弁士様、まこ様
まこ様の質問に触発されて、異体字・サロゲートペアの勉強を再開してみました。
xp時代からの、皆さんのwebの情報をもとに自分なりに勉強しています。
2人のやりとりは、非常に勉強になりました。
昔の、魔界の仮面弁士様のwebで、フォントにグリフ?が、ある・なしを調べるVB.NETにたどり着き、
'http://bbs.wankuma.com/index.cgi?mode=al2&namber=79406&KLOG=135
試してみたくなったのですが、サロゲートペア以上のUTF-16が2つ以上の文字の確認方法というか、
ContainsKey(値)の、値の渡し方がわかりませんでした。
確認したいUTF-16が2つ以上の文字の、コードポイントや、UTF-16の文字列は、自分でサンプル抽出できます(下記)
VBAだと、chrW(a) & chrW(b) & chrW(c) みたいに値を渡すだと思うのですが、
それがVB.NETのintegerに渡すとなると、どうしたらいいのかわかりません。
よかったら御教授いただきたいです。
自分で、サンプル文字のコードなどを確認できる式は、下記で、エクセル2016のVBAです。
MAINを動かすとサンプル例が表示されます。
1回で表示できなかったので、2回にわけます
Public SCA1() As String
Public SCA2() As Long
Public SEL1() As String
Public SEL2() As Long
Sub MAIN()
Call IVDINI(A)
Cells(2, 2).VALUE = "通常"
Cells(3, 2).VALUE = "サロゲートペア"
Cells(4, 2).VALUE = "通常異体字"
Cells(5, 2).VALUE = "サロゲートペア異体字"
Cells(6, 2).VALUE = "結合文字"
Cells(7, 2).VALUE = "有るセレクタ"
Cells(8, 2).VALUE = "嘘のセレクタ"
Cells(2, 4).VALUE = "折"
Cells(3, 4).VALUE = uni2(55405, 57158)
Cells(4, 4).VALUE = uni3(33883, 56128, 56576)
Cells(5, 4).VALUE = uni4(55362, 57247, 56128, 56576)
Cells(6, 4).VALUE = uni5(9977, 65039, 8205, 9792, 65039)
Cells(7, 4).VALUE = uni4(55399, 56893, 56128, 56577)
Cells(8, 4).VALUE = uni4(55399, 56893, 56128, 56586)
For y = 2 To 8
Cells(y, 3).FormulaR1C1 = "=IsIVSHEXSCAL(RC[1])"
Next
End Sub
Function IsIVSHEXSCAL(ByVal VALUE)
'http://d.hatena.ne.jp/replication/20091016/1255704497
Dim bytes, intI, firstByte, secondByte
Dim SEL As Long
Dim SELU As String
Dim IVSByte() As Long
Dim c As Long
bytes = LenB(VALUE) ' バイト数を取得する
ReDim IVSByte(Int(bytes / 2) + 1)
' バイト数だけ繰り返し
IsIVSHEXSCAL = ""
For intI = 1 To bytes Step 2
' 2バイトずつ取り出し
IVSByte(Int(intI / 2)) = AscW(MidB(VALUE, intI, 2))
' 最後のバイトの場合は、secondByteに0を格納する
If intI + 2 < bytes Then
IVSByte(Int(intI / 2) + 1) = AscW(MidB(VALUE, intI + 2, 2))
Else
IVSByte(Int(intI / 2) + 1) = 0
End If
IsIVSHEXSCAL = IsIVSHEXSCAL & "U+" & Application.Dec2Hex(ASCW2(IVSByte(Int(intI / 2))), 4) & ","
Next
c = Application.WorksheetFunction.unicode(VALUE)
'異体字セレクタの確認
'http://mrxray.on.coocan.jp/Delphi/Others/SurrogatePair.htm
If UBound(IVSByte, 1) > 2 Then
If IVSByte(UBound(IVSByte, 1) - 3) = -9408 Then
'上位ワードは U + DB40 の固定値
SEL = Application.Hex2Dec("E0100") + IVSByte(UBound(IVSByte, 1) - 2) + 8960
'U + E0100 ~ U + E01EF
SELU = ",U+" & Application.Dec2Hex(SEL) & IVD(c, (IVSByte(UBound(IVSByte, 1) - 2) + 8960))
Else
SELU = ""
End If
Else
SELU = ""
End If
'https://www.moug.net/tech/exvba/0100035.html
IsIVSHEXSCAL = "(" & "U+" & Application.Dec2Hex(c, 6) & SELU & ")" & IsIVSHEXSCAL
End Function
解決でお願いします