SQLのクエリについて

投稿者 魔界の仮面弁士 (社会人)
投稿日時
2022/6/9 15:12:26
> 集計時に用いるクエリの条件部分(Whereなど)
WHERE に関しては、パラメーターの組み方次第で固定化できるケースはありますね。
たとえばこんな感じで。
文字列として SQL 内に直接埋め込むとサニタイジングが必要になってくるので、
基本的にはパラメータークエリーとしています。その方が SQL 最適化もかかりやすいですし。
> みなさんはどのように運用されていますか?
動的に SQL を作成する場合は、Dapper.NET を併用することが多いです。
階層構造のデータなども効率よくオブジェクト化できるので、
N 層アーキテクチャのアプリでは結構便利です。
(VB の構文だと記述が冗長的になってしまうので、データ層は C# で書くことが多いです)
まぁ、実行結果を DataSet に受け取るようなケースでは、
Dapper を使わずに素の ADO.NET だけで十分だったりはしますが。
WHERE に関しては、パラメーターの組み方次第で固定化できるケースはありますね。
たとえばこんな感じで。
WHERE (@p1 IS NULL OR T1.COL1 = @p1)
AND (@p2 IS NULL OR T1.COL2 = @p2)
AND (@p2 IS NULL OR T1.COL2 = @p2)
文字列として SQL 内に直接埋め込むとサニタイジングが必要になってくるので、
基本的にはパラメータークエリーとしています。その方が SQL 最適化もかかりやすいですし。
> みなさんはどのように運用されていますか?
動的に SQL を作成する場合は、Dapper.NET を併用することが多いです。
階層構造のデータなども効率よくオブジェクト化できるので、
N 層アーキテクチャのアプリでは結構便利です。
(VB の構文だと記述が冗長的になってしまうので、データ層は C# で書くことが多いです)
まぁ、実行結果を DataSet に受け取るようなケースでは、
Dapper を使わずに素の ADO.NET だけで十分だったりはしますが。
投稿者 るきお (社会人)
投稿日時
2022/6/9 21:12:38
私は直接文字列でSQLをプログラム内に埋め込むのが好きですが、少数派かもしれません。
ただ、データアクセス層とビジネスロジック層またはU層は明確に分離し、データアクセス層の外にはモデルとしてデータを公開するアプローチをとります。
(Dapperなどこの仕組みを効率よく実現するものも存在します。)
こうすることでプログラムの部分部分で役割が明確になり、デバッグ・分業等がやりやすくなります。
開発チーム内で反対意見が出るようであれば、文字列としてSQLを埋め込むことを強く主張はしません。
最近はEntity Frameworkを使う事例も多いようです。(これを使ったからと言ってSQLから完全にお別れできるわけではありませんが)。Entity Frameworkを使用するには勉強が必要です。
https://docs.microsoft.com/ja-jp/dotnet/framework/data/adonet/ef/
SQLをプログラムに埋め込む場合でも、魔界の仮面弁士さんが指摘しているように、パラメーター化は必ずやります。これは、業務システムのプログラマーの間では常識となっており、パラメーター化なしで文字列のSQLをプログラムで組み立てて実行するプログラムを書くプログラマーは現場では注意を受けると思います。
Webシステムの場合、脆弱性の原因になるので発注主から訴えられるリスクすらあります。
ただ、データアクセス層とビジネスロジック層またはU層は明確に分離し、データアクセス層の外にはモデルとしてデータを公開するアプローチをとります。
(Dapperなどこの仕組みを効率よく実現するものも存在します。)
こうすることでプログラムの部分部分で役割が明確になり、デバッグ・分業等がやりやすくなります。
開発チーム内で反対意見が出るようであれば、文字列としてSQLを埋め込むことを強く主張はしません。
最近はEntity Frameworkを使う事例も多いようです。(これを使ったからと言ってSQLから完全にお別れできるわけではありませんが)。Entity Frameworkを使用するには勉強が必要です。
https://docs.microsoft.com/ja-jp/dotnet/framework/data/adonet/ef/
SQLをプログラムに埋め込む場合でも、魔界の仮面弁士さんが指摘しているように、パラメーター化は必ずやります。これは、業務システムのプログラマーの間では常識となっており、パラメーター化なしで文字列のSQLをプログラムで組み立てて実行するプログラムを書くプログラマーは現場では注意を受けると思います。
Webシステムの場合、脆弱性の原因になるので発注主から訴えられるリスクすらあります。
投稿者 SSD (社会人)
投稿日時
2022/6/10 13:14:51
魔界の仮面弁士 様
すみません、言い方を間違えました。
仰る通りにWHERE句は固定にしています。
DECLEAR @(変数名) = (値)
SELECT ...
FROM ...
WHERE ...
の(値)の部分だけ動的に変化させてます
なので、この変数宣言句を含む行だけコメントアウトしてsqlファイルに保存し、
アプリケーションでこのファイルから文字列を取得&
"DECLEAR @(変数名) = (値)"を文字列として先頭に追加((値)はフォームから取得した値を入れる)、
という感じのことをしています。
パラメータークエリというのを初めて知ったので調べてみました。
https://hosopro.blogspot.com/2016/09/parameters-query.html
こちらのサイトから該当する部分だけ抜粋させて頂きました。
以下の部分で間違いないでしょうか?
----------
'データソースで実行するTransact-SQLステートメントを指定
cmd.CommandText = "SELECT [ID], [Name], [Type] FROM [T_Animals] WHERE [Type] = @Type"
cmd.Parameters.Clear()
'パラメータ値を設定
cmd.Parameters.Add("@Type", System.Data.SqlDbType.NVarChar, 50).Value = "猫"
----------
これですと私がしているような変数宣言句を追加しなくてもできますね。
こちらの方がスマートな感じがします。
この紹介されているコードでは
"SELECT [ID], [Name], [Type] FROM [T_Animals] WHERE [Type] = @Type"
というクエリ本体(?)部分はコード内に直に書いてあります。
結合がある場合や、条件が分岐する場合などはもっと長いクエリになるので、
直にコードに書くというのはインテリセンスもなく、検証もしにくいと思います。
元々はGUI(SQL Server Management StudioやAzure Data Studioなど)で編集しておいて、
それをコード内にコピペするんでしょうか?
それとも別の方法で運用するのが一般的でしょうか?
ということを聞きたかったのが本題です。
Dapperについても調べてみましたが、こちらは主に取得したレコードの列とクラスのパラメーターを
マッピングするのが便利な機能という感じでしょうか?
すみません、言い方を間違えました。
仰る通りにWHERE句は固定にしています。
DECLEAR @(変数名) = (値)
SELECT ...
FROM ...
WHERE ...
の(値)の部分だけ動的に変化させてます
なので、この変数宣言句を含む行だけコメントアウトしてsqlファイルに保存し、
アプリケーションでこのファイルから文字列を取得&
"DECLEAR @(変数名) = (値)"を文字列として先頭に追加((値)はフォームから取得した値を入れる)、
という感じのことをしています。
パラメータークエリというのを初めて知ったので調べてみました。
https://hosopro.blogspot.com/2016/09/parameters-query.html
こちらのサイトから該当する部分だけ抜粋させて頂きました。
以下の部分で間違いないでしょうか?
----------
'データソースで実行するTransact-SQLステートメントを指定
cmd.CommandText = "SELECT [ID], [Name], [Type] FROM [T_Animals] WHERE [Type] = @Type"
cmd.Parameters.Clear()
'パラメータ値を設定
cmd.Parameters.Add("@Type", System.Data.SqlDbType.NVarChar, 50).Value = "猫"
----------
これですと私がしているような変数宣言句を追加しなくてもできますね。
こちらの方がスマートな感じがします。
この紹介されているコードでは
"SELECT [ID], [Name], [Type] FROM [T_Animals] WHERE [Type] = @Type"
というクエリ本体(?)部分はコード内に直に書いてあります。
結合がある場合や、条件が分岐する場合などはもっと長いクエリになるので、
直にコードに書くというのはインテリセンスもなく、検証もしにくいと思います。
元々はGUI(SQL Server Management StudioやAzure Data Studioなど)で編集しておいて、
それをコード内にコピペするんでしょうか?
それとも別の方法で運用するのが一般的でしょうか?
ということを聞きたかったのが本題です。
Dapperについても調べてみましたが、こちらは主に取得したレコードの列とクラスのパラメーターを
マッピングするのが便利な機能という感じでしょうか?
投稿者 SSD (社会人)
投稿日時
2022/6/10 14:21:48
るきお 様
魔界の仮面弁士さんに返信した際に申し上げたのですが、
今やっていることはパラメータークエリっぽくはなっていると思います。
(やり方は大分格好悪いですが)
るきおさんは直接コードに書かれるということですが、インテリセンスが無くて不便ではないですか?
魔界の仮面弁士さんに返信した際に申し上げたのですが、
今やっていることはパラメータークエリっぽくはなっていると思います。
(やり方は大分格好悪いですが)
るきおさんは直接コードに書かれるということですが、インテリセンスが無くて不便ではないですか?
投稿者 SSD (社会人)
投稿日時
2022/6/10 14:29:49
るきお 様
層について分からなかったので以下で調べました。
https://atmarkit.itmedia.co.jp/fdotnet/vblab/bizappbasic02/bizappbasic02_01.html#:~:text=%E3%83%87%E3%83%BC%E3%82%BF%E3%83%BB%E3%82%A2%E3%82%AF%E3%82%BB%E3%82%B9%E5%B1%A4%E3%81%A7%E3%81%AF%E3%80%81%E3%83%87%E3%83%BC%E3%82%BF,%E3%82%92%E3%81%99%E3%82%8B%E5%A0%B4%E5%90%88%E3%82%82%E3%81%82%E3%82%8B%E3%80%82
役割を明確に(3層に)分けてシステム内部で分業化させるということは分かりました。
> データアクセス層の外にはモデルとしてデータを公開するアプローチをとります。
について
"データアクセス層の外"とはどこのことでしょうか?
"モデルとしてデータを公開する"とは具体的に何が何をすることでしょうか?
この一文が理解できなかったので、具体的に教えて頂けないでしょうか?
層について分からなかったので以下で調べました。
https://atmarkit.itmedia.co.jp/fdotnet/vblab/bizappbasic02/bizappbasic02_01.html#:~:text=%E3%83%87%E3%83%BC%E3%82%BF%E3%83%BB%E3%82%A2%E3%82%AF%E3%82%BB%E3%82%B9%E5%B1%A4%E3%81%A7%E3%81%AF%E3%80%81%E3%83%87%E3%83%BC%E3%82%BF,%E3%82%92%E3%81%99%E3%82%8B%E5%A0%B4%E5%90%88%E3%82%82%E3%81%82%E3%82%8B%E3%80%82
役割を明確に(3層に)分けてシステム内部で分業化させるということは分かりました。
> データアクセス層の外にはモデルとしてデータを公開するアプローチをとります。
について
"データアクセス層の外"とはどこのことでしょうか?
"モデルとしてデータを公開する"とは具体的に何が何をすることでしょうか?
この一文が理解できなかったので、具体的に教えて頂けないでしょうか?
投稿者 (削除されました) ()
投稿日時
2022/6/10 14:29:50
(削除されました)
投稿者 SSD (社会人)
投稿日時
2022/6/10 14:32:33
訂正
誤)DECLEAR
正)DECLARE
誤)DECLEAR
正)DECLARE
投稿者 魔界の仮面弁士 (社会人)
投稿日時
2022/6/10 14:51:47
> というクエリ本体(?)部分はコード内に直に書いてあります。
長い処理は SQL を直接書くのではなく、データベース側のストアドにしておいて、
Dapper (というか ADO.NET) に渡すのはストアドの名前(とパラメーター)を渡すだけであり、
長い SQL 文がソースに含まれるわけではありません。
ストアドにしておくと、SSMS などからステップ実行できたりしますし、
ストアドの修正だけで済む場合は、EXE のリコンパイルが不要にもなります。
ただしストアドの数が増えすぎないように注意する必要はありますけれどね。
対 Oracle であれば、ストアド パッケージにまとめられるのですが…。
> で編集しておいて、それをコード内にコピペするんでしょうか?
ストアドを使わない場合、泥臭いですが自分はそのパターンですね。
型付 DataSet の TableAdapter で済ませることもあります。
(TableAdapter は、複雑なクエリーになると扱い辛いんですが)。
My.Resources に埋め込む手法を使ったこともあるのですが、
これだと複数人で開発する場合に管理しにくかった…。
外部ファイルから実行時に読み取る方法をとることもありましたが、
ファイル管理が分かりにくくなるので辞めてしまいました。
長い処理は SQL を直接書くのではなく、データベース側のストアドにしておいて、
Dapper (というか ADO.NET) に渡すのはストアドの名前(とパラメーター)を渡すだけであり、
長い SQL 文がソースに含まれるわけではありません。
ストアドにしておくと、SSMS などからステップ実行できたりしますし、
ストアドの修正だけで済む場合は、EXE のリコンパイルが不要にもなります。
ただしストアドの数が増えすぎないように注意する必要はありますけれどね。
対 Oracle であれば、ストアド パッケージにまとめられるのですが…。
> で編集しておいて、それをコード内にコピペするんでしょうか?
ストアドを使わない場合、泥臭いですが自分はそのパターンですね。
型付 DataSet の TableAdapter で済ませることもあります。
(TableAdapter は、複雑なクエリーになると扱い辛いんですが)。
My.Resources に埋め込む手法を使ったこともあるのですが、
これだと複数人で開発する場合に管理しにくかった…。
外部ファイルから実行時に読み取る方法をとることもありましたが、
ファイル管理が分かりにくくなるので辞めてしまいました。
投稿者 SSD (社会人)
投稿日時
2022/6/10 16:03:21
魔界の仮面弁士 様
ストアドプロシージャというのがあるのですね。
調べてみましたがとても便利そうです。
> ただしストアドの数が増えすぎないように注意する必要はありますけれどね。
とありますが、その数の基準は何でしょうか?
今のところ外部に保存してあるsqlファイルは40ほどありますので、
ストアドプロシージャも同じ数になりそうなのですがこれは多いでしょうか?
ストアドプロシージャというのがあるのですね。
調べてみましたがとても便利そうです。
> ただしストアドの数が増えすぎないように注意する必要はありますけれどね。
とありますが、その数の基準は何でしょうか?
今のところ外部に保存してあるsqlファイルは40ほどありますので、
ストアドプロシージャも同じ数になりそうなのですがこれは多いでしょうか?
投稿者 魔界の仮面弁士 (社会人)
投稿日時
2022/6/10 18:14:56
> その数の基準は何でしょうか?
具体的な基準数があるわけではないのですが、自分が関わっているシステムは、
いずれもテーブル数だけで 650~900 ほどある規模のものです。
(外部データベースのテーブルやビューなども含めると、もっと多いですが)
> 今のところ外部に保存してあるsqlファイルは40ほどありますので
その程度なら問題無いと思いますよ。十分に管理できる数だと思います。
> ストアドプロシージャというのがあるのですね。
SQL Server のストアド プロシージャーやストアド ファンクションは、
VB で言うところの「Module 内の Sub や Function」に相当するイメージですね。
自分が良く使っているのは Oracle というデータベースです。
こちらにもストアド プロシージャーやストアド ファンクションがありますが、
その他、ストアドパッケージというものもあります。
パッケージとは VB でいう「クラス」に相当する物で、PACKAGE の中に、
複数の PROCEDURE や FUNCTION を収めることができます(メソッドのイメージです)。
各メソッドを非公開/公開(VB の Private / Public に相当)状態にできますし、
パッケージ上に「フィールド変数」を保持させることもできるという代物です。
管理しやすくなるので、自分はパッケージをよく利用しています。
ただ、SQL Server にはパッケージが無いので、
>> ただしストアドの数が増えすぎないように注意する必要はありますけれどね。
とつぶやいてしまいました。Oracle → SQL Server への移植時に
互換性を持たせようとして、プロシージャ数が一気に増えて苦労したもので…。
(といっても、プロシージャ数は 4 桁で収まりましたが)
具体的な基準数があるわけではないのですが、自分が関わっているシステムは、
いずれもテーブル数だけで 650~900 ほどある規模のものです。
(外部データベースのテーブルやビューなども含めると、もっと多いですが)
> 今のところ外部に保存してあるsqlファイルは40ほどありますので
その程度なら問題無いと思いますよ。十分に管理できる数だと思います。
> ストアドプロシージャというのがあるのですね。
SQL Server のストアド プロシージャーやストアド ファンクションは、
VB で言うところの「Module 内の Sub や Function」に相当するイメージですね。
自分が良く使っているのは Oracle というデータベースです。
こちらにもストアド プロシージャーやストアド ファンクションがありますが、
その他、ストアドパッケージというものもあります。
パッケージとは VB でいう「クラス」に相当する物で、PACKAGE の中に、
複数の PROCEDURE や FUNCTION を収めることができます(メソッドのイメージです)。
各メソッドを非公開/公開(VB の Private / Public に相当)状態にできますし、
パッケージ上に「フィールド変数」を保持させることもできるという代物です。
管理しやすくなるので、自分はパッケージをよく利用しています。
ただ、SQL Server にはパッケージが無いので、
>> ただしストアドの数が増えすぎないように注意する必要はありますけれどね。
とつぶやいてしまいました。Oracle → SQL Server への移植時に
互換性を持たせようとして、プロシージャ数が一気に増えて苦労したもので…。
(といっても、プロシージャ数は 4 桁で収まりましたが)
投稿者 るきお (社会人)
投稿日時
2022/6/10 21:29:36
> るきおさんは直接コードに書かれるということですが、インテリセンスが無くて不便ではないですか?
あったら便利だなとは思いますが、あきらめて受け入れています。
複雑なクエリはSSDさんと同様でツールで作成したものをVisual Studioに貼り付けたりします。
私の場合は、SQL Server Management Studioを使う場合が多いです。
>"データアクセス層の外"とはどこのことでしょうか?
>"モデルとしてデータを公開する"とは具体的に何が何をすることでしょうか?
たとえば、このようにプロジェクトを3つに分けます。(業務ロジック専用のプロジェクトや、WebAPIの通信用のプロジェクトなどさらに分ける場合もあります。)
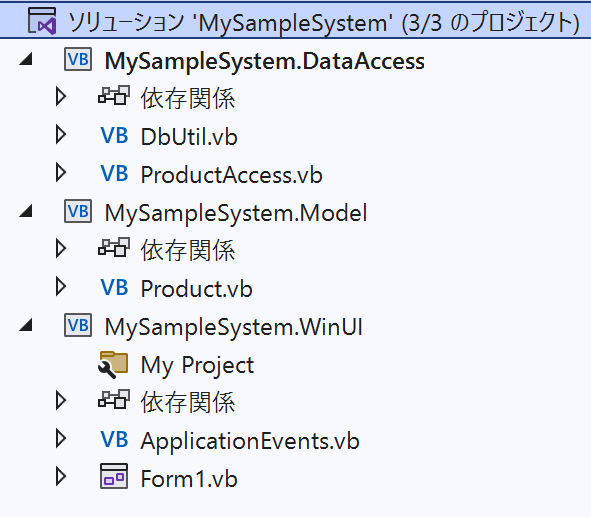
MySampleSystem.Modelプロジェクトには主に業務で使用するデータ構造だけを記したシンプルなクラスを定義します。これを「モデル」と呼びます。たとえば、このような感じです。
MySampleSystem.DataAccessプロジェクトはデータアクセス層です。データベースにアクセスするプログラムはすべてここに記述します。
たとえば、このような感じです。
MySampleSystem.WinUIプロジェクトはUI層です。
データを操作する場合、このプロジェクトでは直接データベースにアクセスするのではなく、データアクセス層(MySampleSystem.DataAccess)に依頼します。
たとえば、このような感じです。
この構造によってUI層はデータベースとは完全に切り離され、ただ Model.Product というクラス(モデル)を介してのみデータと接点を持つことになります。
これが「モデルとしてデータを公開する」という意味です。
「データアクセス層の外」とはUI層など、別のレイヤーを指します。
システムをこのような構造にすることで、デバッグや分業がやりやすくなり、コードの再利用や、機能追加・保守などの柔軟性が高まります。
たとえば、後になってWeb用の画面も作りたいと思った場合、データアクセス層はそのまま流用できます。
データベースの項目の大きな変更があった場合、データアクセス層のプログラムだけ変更・テストすれば、UI層は無影響で済むかもしれません。
開発中によくわからないバグが発生しているときに、データの取得に問題があるのか、画面の制御に問題があるのか、問題を切り分けやすくなります。
あったら便利だなとは思いますが、あきらめて受け入れています。
複雑なクエリはSSDさんと同様でツールで作成したものをVisual Studioに貼り付けたりします。
私の場合は、SQL Server Management Studioを使う場合が多いです。
>"データアクセス層の外"とはどこのことでしょうか?
>"モデルとしてデータを公開する"とは具体的に何が何をすることでしょうか?
たとえば、このようにプロジェクトを3つに分けます。(業務ロジック専用のプロジェクトや、WebAPIの通信用のプロジェクトなどさらに分ける場合もあります。)
MySampleSystem.Modelプロジェクトには主に業務で使用するデータ構造だけを記したシンプルなクラスを定義します。これを「モデル」と呼びます。たとえば、このような感じです。
''' <summary>商品</summary>
Public Class Product
''' <summary>商品コード</summary>
Public Property ProductCode As String
''' <summary>商品名</summary>
Public Property ProductName As String
''' <summary>現行品区分</summary>
Public Property IsActive As Boolean
End ClassMySampleSystem.DataAccessプロジェクトはデータアクセス層です。データベースにアクセスするプログラムはすべてここに記述します。
たとえば、このような感じです。
Public Class ProductAccess
''' <summary>商品コードを指定して、該当する商品を取得します。</summary>
Public Function GetProduct(productCode As String) As Model.Product
Using command As New Microsoft.Data.SqlClient.SqlCommand
command.CommandText = "SELECT * FROM T_PRODUCT WHERE productCode = @productCode"
command.Parameters.Add("@productCode", Data.SqlDbType.NVarChar).Value = productCode
Using table As Data.DataTable = DbUtil.Select(command)
Dim result As New Model.Product
result.ProductCode = CStr(table.Rows(0)("ProductCode"))
result.ProductName = CStr(table.Rows(0)("ProductName"))
result.IsActive = CBool(table.Rows(0)("IsActive"))
Return result
End Using
End Using
End Function
''' <summary>商品コードから商品を検索します。該当する商品の一覧を返します。</summary>
''' <param name="partOfproductCode">検索する商品コードの一部</param>
Public Function FindProduct(partOfproductCode As String) As List(Of Model.Product)
Using command As New Microsoft.Data.SqlClient.SqlCommand
command.CommandText = "SELECT * FROM T_PRODUCT WHERE productCode LIKE CONCAT( N'%', @productCode, N'%' )"
command.Parameters.Add("@productCode", Data.SqlDbType.NVarChar).Value = partOfproductCode
Using table As Data.DataTable = DbUtil.Select(command)
Dim results As New List(Of Model.Product)
For Each row As Data.DataRow In table.Rows
Dim result As New Model.Product
result.ProductCode = CStr(row("ProductCode"))
result.ProductName = CStr(row("ProductName"))
result.IsActive = CBool(row("IsActive"))
results.Add(result)
Next
Return results
End Using
End Using
End Function
End ClassMySampleSystem.WinUIプロジェクトはUI層です。
データを操作する場合、このプロジェクトでは直接データベースにアクセスするのではなく、データアクセス層(MySampleSystem.DataAccess)に依頼します。
たとえば、このような感じです。
Private Sub btnSearch_Click(sender As Object, e As EventArgs) Handles btnSearch.Click
Dim productAccess As New DataAccess.ProductAccess
Dim results As List(Of Model.Product) = productAccess.FindProduct(txtProductCode.Text)
MsgBox($"{results.Count} 件ヒットしました。")
MsgBox($"1件目 {results(0).ProductName}")
End Subこの構造によってUI層はデータベースとは完全に切り離され、ただ Model.Product というクラス(モデル)を介してのみデータと接点を持つことになります。
これが「モデルとしてデータを公開する」という意味です。
「データアクセス層の外」とはUI層など、別のレイヤーを指します。
システムをこのような構造にすることで、デバッグや分業がやりやすくなり、コードの再利用や、機能追加・保守などの柔軟性が高まります。
たとえば、後になってWeb用の画面も作りたいと思った場合、データアクセス層はそのまま流用できます。
データベースの項目の大きな変更があった場合、データアクセス層のプログラムだけ変更・テストすれば、UI層は無影響で済むかもしれません。
開発中によくわからないバグが発生しているときに、データの取得に問題があるのか、画面の制御に問題があるのか、問題を切り分けやすくなります。
投稿者 るきお (社会人)
投稿日時
2022/6/10 21:30:29
ただし、この構造は今では少し古臭い感じはします。これが適しているかもケースバイケースです。あまり規模が大きくないシステム(システムというよりはツールのようなレベル)では、面倒が増えるだけかもしれません。
巷のシステム開発会社に開発を依頼するとだいたいここで紹介するような階層(レイヤー)で作ってくれると思います。
最近では、クラウドを使ったマイクロサービスアーキテクチャーの方がモダンです。(これが適するかもケースバイケースですが)
これは1個の巨大なソリューションを作るのではなく、単機能の小さな Azure Functions などを多く作ってそれぞれ連携させることで、大きな機能を実現させるというアプローチです。
※なお、前の投稿で紹介したプログラム例はイメージを伝えるためだけに即席で書いたものです。
巷のシステム開発会社に開発を依頼するとだいたいここで紹介するような階層(レイヤー)で作ってくれると思います。
最近では、クラウドを使ったマイクロサービスアーキテクチャーの方がモダンです。(これが適するかもケースバイケースですが)
これは1個の巨大なソリューションを作るのではなく、単機能の小さな Azure Functions などを多く作ってそれぞれ連携させることで、大きな機能を実現させるというアプローチです。
※なお、前の投稿で紹介したプログラム例はイメージを伝えるためだけに即席で書いたものです。
投稿者 るきお (社会人)
投稿日時
2022/6/10 21:32:41
LIKEでのパラメータクエリを検索したら魔界の仮面弁士さんの別の書き込みがヒットしました。
使わせてもらいました。
https://social.msdn.microsoft.com/forums/ja-JP/bb4aebcf-c3ab-4099-ba9d-091a372578fc/12497125211251312540124791243421033299921237512383like1239127442?forum=vbgeneralja
使わせてもらいました。
https://social.msdn.microsoft.com/forums/ja-JP/bb4aebcf-c3ab-4099-ba9d-091a372578fc/12497125211251312540124791243421033299921237512383like1239127442?forum=vbgeneralja
投稿者 SSD (社会人)
投稿日時
2022/6/13 09:31:07
魔界の仮面弁士 様
ありがとうございます。
ストアドプロシージャを使ってみようと思います。
ありがとうございます。
ストアドプロシージャを使ってみようと思います。
投稿者 SSD (社会人)
投稿日時
2022/6/13 11:03:22
るきお 様
ご説明頂き理解できました。
ありがとうございます。
マイクロサービスにした場合は、例示して頂いたようなプロジェクトはどのようになるのでしょうか?
マイクロサービスは単独で完結しているものと理解しました。
データアクセス層とUI層ではどちらもモデルを用いていますが、
単独で完結するマイクロサービスでは共通となるモデルは用いずに、
それぞれのサービスで独自のモデルに相当するクラスを定義することになるのでしょうか?
ご説明頂き理解できました。
ありがとうございます。
マイクロサービスにした場合は、例示して頂いたようなプロジェクトはどのようになるのでしょうか?
マイクロサービスは単独で完結しているものと理解しました。
データアクセス層とUI層ではどちらもモデルを用いていますが、
単独で完結するマイクロサービスでは共通となるモデルは用いずに、
それぞれのサービスで独自のモデルに相当するクラスを定義することになるのでしょうか?
投稿者 SSD (社会人)
投稿日時
2022/6/13 11:04:49
解決にチェックをつけ忘れてしまったのでここで付けます。
投稿者 SSD (社会人)
投稿日時
2022/6/13 16:08:12
るきお 様
Using table As Data.DataTable = DbUtil.Select(command)
のDbUtil.Selectは共有メソッドですか?
オブジェクトブラウザーとかで調べてみたんですがわからなかったので教えていただけないでしょうか。
Using table As Data.DataTable = DbUtil.Select(command)
のDbUtil.Selectは共有メソッドですか?
オブジェクトブラウザーとかで調べてみたんですがわからなかったので教えていただけないでしょうか。
投稿者 るきお (社会人)
投稿日時
2022/6/13 21:19:06
>Using table As Data.DataTable = DbUtil.Select(command)
>のDbUtil.Selectは共有メソッドですか?
はい。そして、DbUtilクラスは私がサンプル用に作ったクラスです。
私が貼り付けた画像でMySampleSystem.DataAccessプロジェクトにDbUtilクラスがあるのをご確認いただけます。
SQLの実行や、SQLの結果の取得は決まりきったコードなので、大したコードではありませんが、このようにユーティリティー化して利用するプロジェクトが多いように思います。
>マイクロサービスにした場合は、例示して頂いたようなプロジェクトはどのようになるのでしょうか?
>マイクロサービスは単独で完結しているものと理解しました。
いいえ。マイクロサービスアーキテクチャーは細かいものを連携させて1つのシステムにします。
マイクロサービスアーキテクチャーはやや高度なトピックです。
向いているシステムとそうでないシステムもありますので、あまり深入りしなくてもよいと思います。
参考資料
https://docs.microsoft.com/ja-jp/dotnet/architecture/microservices/architect-microservice-container-applications/microservices-architecture
>単独で完結するマイクロサービスでは共通となるモデルは用いずに、
>それぞれのサービスで独自のモデルに相当するクラスを定義することになるのでしょうか?
マイクロサービスアーキテクチャーではJSONがデータ形式の主役になります。
それをVB側ではモデルとしてもよいですし、動的に利用してもよいです。
>のDbUtil.Selectは共有メソッドですか?
はい。そして、DbUtilクラスは私がサンプル用に作ったクラスです。
私が貼り付けた画像でMySampleSystem.DataAccessプロジェクトにDbUtilクラスがあるのをご確認いただけます。
SQLの実行や、SQLの結果の取得は決まりきったコードなので、大したコードではありませんが、このようにユーティリティー化して利用するプロジェクトが多いように思います。
>マイクロサービスにした場合は、例示して頂いたようなプロジェクトはどのようになるのでしょうか?
>マイクロサービスは単独で完結しているものと理解しました。
いいえ。マイクロサービスアーキテクチャーは細かいものを連携させて1つのシステムにします。
マイクロサービスアーキテクチャーはやや高度なトピックです。
向いているシステムとそうでないシステムもありますので、あまり深入りしなくてもよいと思います。
参考資料
https://docs.microsoft.com/ja-jp/dotnet/architecture/microservices/architect-microservice-container-applications/microservices-architecture
>単独で完結するマイクロサービスでは共通となるモデルは用いずに、
>それぞれのサービスで独自のモデルに相当するクラスを定義することになるのでしょうか?
マイクロサービスアーキテクチャーではJSONがデータ形式の主役になります。
それをVB側ではモデルとしてもよいですし、動的に利用してもよいです。
投稿者 SSD (社会人)
投稿日時
2022/6/14 13:48:06
るきお 様
完結というのは言い方が悪かったです。
参考資料で述べられているように独立しているという意味合いでした。
少し納得できていなかったというか疑問に思っていたのは、
それぞれが独立している状態で相互にデータをやり取りする場合に、
そのデータの構造はどこで保障されているのか、ということです。
例えばサービスAから出力されるデータαを使うサービスB、Cがあり、
データαの構造が変更されるとサービスB、Cもそれに対応するために
処理内容の変更をしないといけないのでは?
それはそれぞれに独立しているとは言えないのでは?
と疑問に思っていました。
ただ参考資料には
インターフェイスまたはコントラクトを変更しない限り、
任意のマイクロサービスの内部実装を変更することや、
他のマイクロサービスを中断することなく新機能を追加することができます。
と記載されていたので、やりとりするデータの構造などが変更されれば
当然他のサービスにも影響があるが、そうでない限りは新しい機能を追加しても
他のサービスに影響はないという意味で納得しました。
完結というのは言い方が悪かったです。
参考資料で述べられているように独立しているという意味合いでした。
少し納得できていなかったというか疑問に思っていたのは、
それぞれが独立している状態で相互にデータをやり取りする場合に、
そのデータの構造はどこで保障されているのか、ということです。
例えばサービスAから出力されるデータαを使うサービスB、Cがあり、
データαの構造が変更されるとサービスB、Cもそれに対応するために
処理内容の変更をしないといけないのでは?
それはそれぞれに独立しているとは言えないのでは?
と疑問に思っていました。
ただ参考資料には
インターフェイスまたはコントラクトを変更しない限り、
任意のマイクロサービスの内部実装を変更することや、
他のマイクロサービスを中断することなく新機能を追加することができます。
と記載されていたので、やりとりするデータの構造などが変更されれば
当然他のサービスにも影響があるが、そうでない限りは新しい機能を追加しても
他のサービスに影響はないという意味で納得しました。
集計時に用いるクエリの条件部分(Whereなど)をユーザーの入力に合わせて
動的に変化させられるように以下のような仕組みにしています。
1.クエリをAzure Data Studioで編集し、
最初の変数宣言部分をコメントアウトして共有フォルダに保存
(*.sqlファイルとして)
2.1のファイルから文字列を取得し、変数の宣言とフォームから取得した値を
それぞれの変数に入れる文字列を先頭に追加
3.2の文字列をクエリとしてコマンド実行し、レコード取得
クエリの検証やインテリセンスを表示させることなどを考えると、
Visual Studioのコード内でクエリを作るのは難しいと考え
この方法をとりました。
みなさんはどのように運用されていますか?
サイトで調べてみると直にコード内にクエリを文字列として書いている例しかなく、
自分のやっていることが正しいのかや、他にはどんな方法があるのか分からなかったので
こちらで質問しました。